Levels of Multilingual Metadata
Metadata records can contain varying levels of multilingual content, ranging in both number of languages represented and number of fields translated. Even if a record only has a single field in a language other than English, it still contains multilingual metadata, represented in the content and in the metadata describing that language.

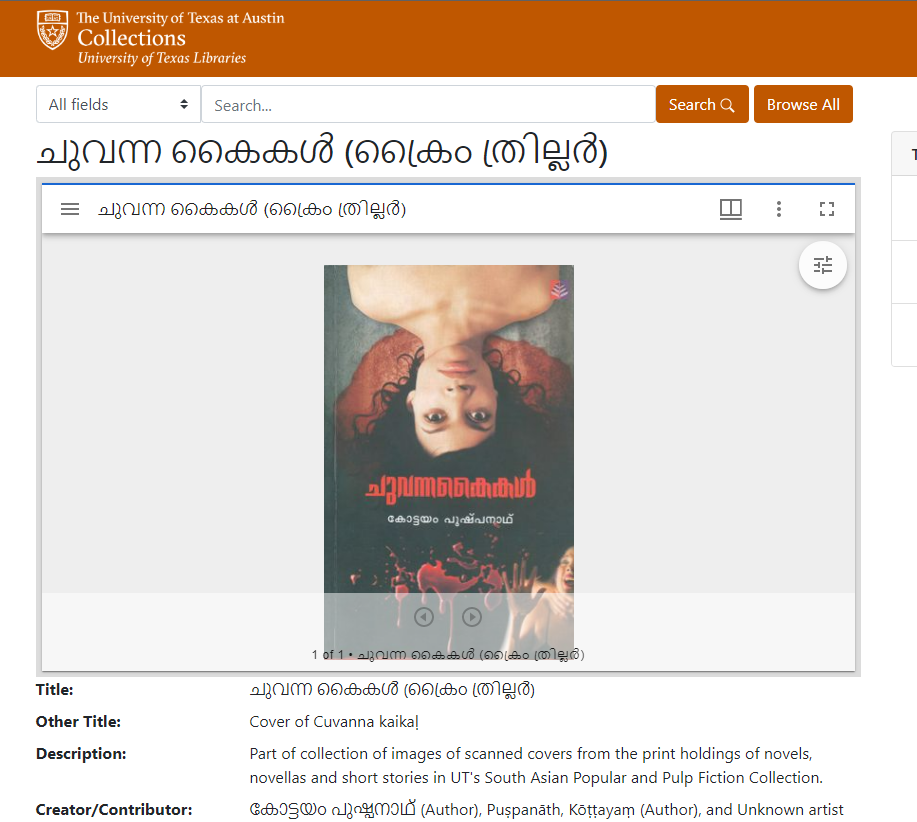
Example of a record with non-roman script; only names in a second language
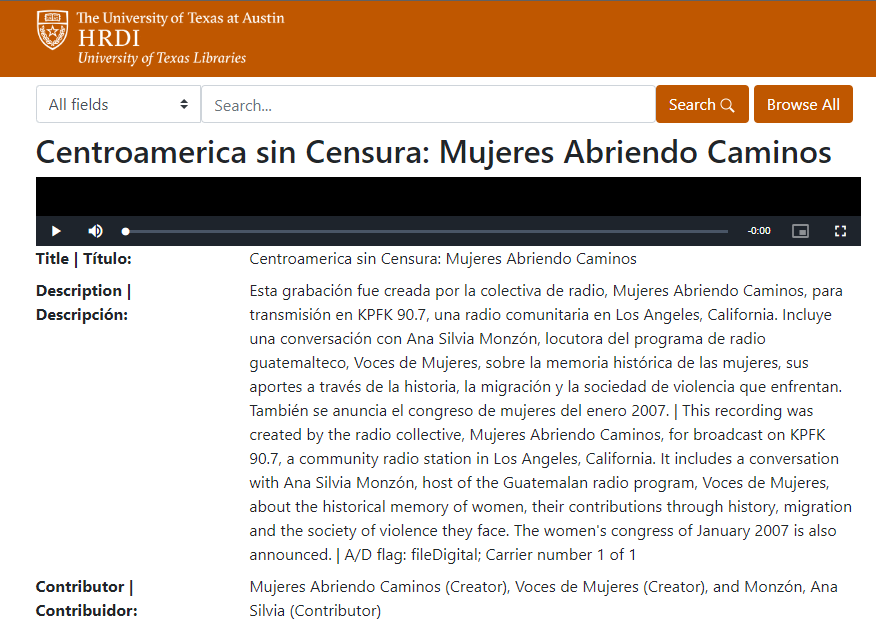
Example of a record fully translated, using roman script
Guidelines
GENERAL GUIDELINES
Languages should be treated with the same equivalency; translations should have as a close relationship to the first language's meaning as possible (this may not always be English.)
If you are providing multilingual metadata beyond titles and proper nouns, ensure that linguistic diversity is respected. Take the time to evaluate terms from different countries/communities that speak that language.
If detailed translation is desired, consider paying for professional translation.
Full translation of the record is a desired goal, but not always possible for materials. Approaching multilingual metadata as a tiered process can help identify what items to translate.
BY FIELD
For Titles and proper nouns (Contributor, Publisher, Subject Name fields, etc.):
Keep the item in its original language; do not translate them to English.
For non-roman script, a transliterated version of the title can be recorded in a second title field so it can have its own language tag. (Subtitles should be reserved for actual subtitles of the title.)
For Subject (Topic, Geographic Place, Temporal fields), Genre, Form/Medium:
These fields can be an easier place to start translation work, as they can be found in existing controlled vocabularies such as the Getty Vocabularies or VIAF.
Evaluate whether the term adequately describes the meaning of the original English concept and if the term is used with high frequency in its context (dialect, country, community, or subject domain can all apply.)
Apply the same terms consistently across materials.
Critical cataloging best practices still apply; you may need to investigate whether certain terms should be used, or to see if remediated English terms have the same meaning as their counterparts in other languages.
For Descriptions and Rights/Citation information:
These fields, while critical, can be more challenging to translate as they require a high degree of familiarity with the language.
Professional translation services can be one way to make this work more sustainable. If these services are not available, translation by UT Austin Libraries workers should be prioritized for frequently accessed materials or those deemed key by collections curators.
Translation of these fields are especially encouraged if usage statistics have found the collections object to be accessed or used by other language communities. For example, some of our collections have translated these fields into Spanish. The origin of these materials, their use in Spanish speaking communities, and the high use of Spanish on UT Austin's campus have demonstrated this need.
Diacritics and Character Encoding
Diacritics are marks or symbols that show the phonetic value of a letter. (Ex. "á" or "ñ")
Character encoding is a process of making those letters machine-readable, assigning numerical codes. The majority of UTL's metadata uses UTF-8 character encoding. When creating metadata spreadsheets or XML, ensure that your character encoding is UTF-8. This will allow your diacritics to be displayed.
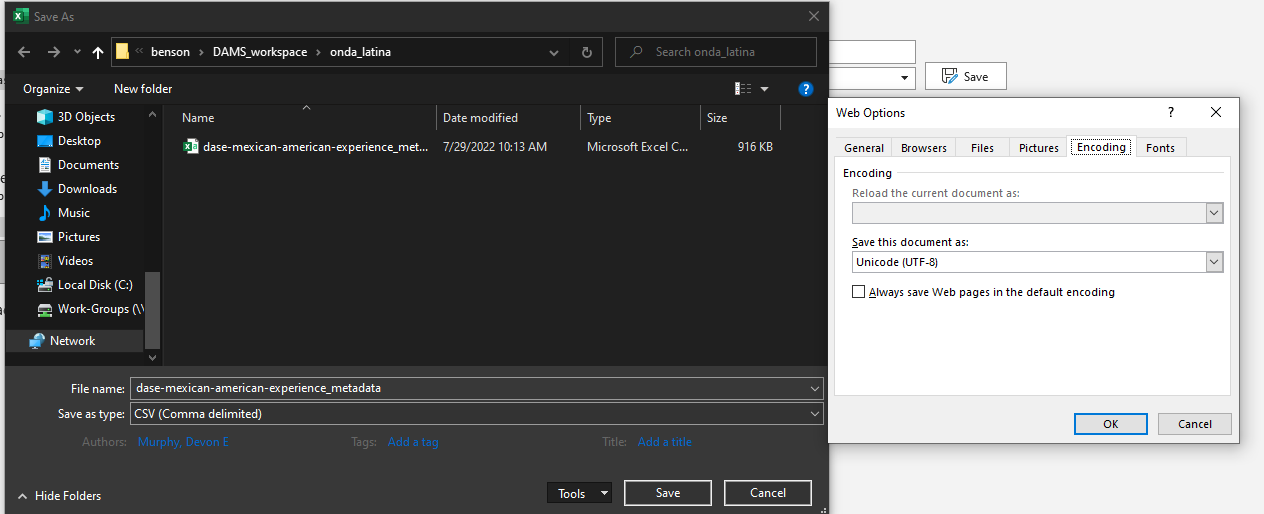
To check the character encoding in an Excel spreadsheet, navigate to the "Save As" option, then choose "Web Options" in the "Tools" dropdown menu.
UTF-8 encoding menu in Excel (Tools→Web Options)
For XML editors like Oxygen, navigating to Preferences→ Encoding will allow you to check the encoding of the document (UTF-8 by default.)
For Google Sheets, documents are in UTF-8 by default.
Metadata Modeling
Languages used in metadata fields are modeled in different ways, based on the metadata schema. Below are a few examples. For more guidance on where to source Language information for the UTL DAMS, see the "Assets" section of the wiki. Currently, ISO 639-3 codes are advised.
In EAD, the language of the finding aid and the language of the material are both represented in separate fields.
In MODS, the language of the finding aid and the language of the material are both represented in separate fields. Language tags are also assigned to individual fields to allow for greater flexibility.
In this JSON example, the language of the material is represented as an array, containing "Spanish, Castilian." The array structure and other key : value pairs allow for multiple languages to be represented.
Ethics, or Multilingual Metadata as Accessibility
Providing multilingual metadata aligns with the libraries' mission to support research and to include IDEA (inclusion, diversity, equity, and accessibility) concepts in all aspects of library work by:
- Developing new access points to the libraries' collections by using languages our students, faculty, and researchers use
- Providing enhanced access to collections that are from locations/communities that speak languages other than English, opening them up to source communities
- Addressing UT Austin's status as a Hispanic Serving Institution by focusing on Spanish and Portuguese translation of collections' metadata
- Encouraging new methods of research by expanding linkages to multilingual vocabularies and linked data sources
Resources
RESOURCES ON METADATA TRANSLATION
ISO-639 code tables (combines parts 1, 2, and 3)
Getty Vocabularies guides to contributing multilingual metadata (Guide 1, Guide 2)
List of Getty Vocabularies translation projects from the International Terminology Working Group
VIAF (Virtual International Authority File)
PANA (Pan-American Authorities project) from the University of Florida Libraries (contains large list of Spanish language thesauri/controlled vocabularies)
ISLANDORA 8 TRANSLATION MULTILINGUAL SUPPORT
Step-by-step guide to full multilingual site configuration
Drupal guide to multilingual content
Example of a record in Islandora 8 that has multilingual fields (in JSON-LD)
EXAMPLES OF TRANSLATED DIGITAL COLLECTIONS SITES AT UT LIBRARIES
Archive of the Indigenous Languages of Latin America (AILLA)
Human Rights Documentation Initiative (HRDI)
Works Cited
Resources used for this page include but are not limited to:
White Paper on Best Practices for Multilingual Access to Digital Libraries from Europeana
Guidelines for the Development and Promotion of Multilingual Collections and Services from RUSA (Reference and User Services Association, part of the American Library Association)
Multilingual Practices in GLAMs Zotero maintained by UTL staff (Devon Murphy, Carla Alvarez, Theresa Polk, Alex Suárez, Karla Roig)
Overview
Content Tools