| Table of Contents |
|---|
Overview
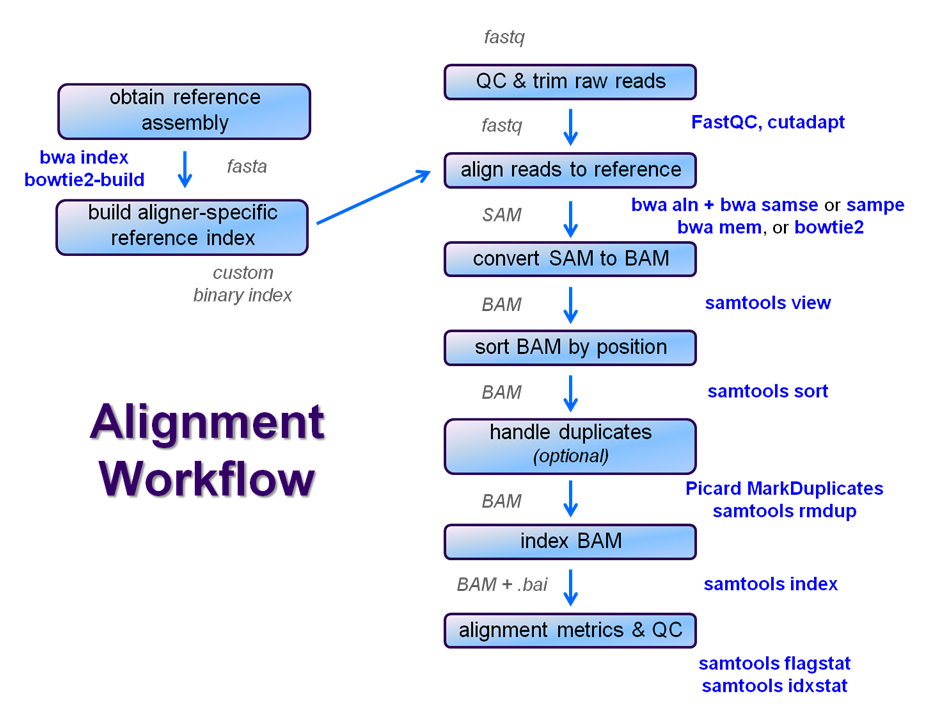
After raw sequence files are generated (in FASTQ format), quality-checked, and pre-processed in some way, the next step in many NGS pipelines is mapping to a reference genome.
...
Even though many mapping tools exist, a few individual programs have a dominant "market share" of the NGS world. In this section, we will primarily focus on two of the most versatile general-purpose ones: BWA and Bowtie2 (the latter being part of the Tuxedo suite which includes the transcriptome-aware RNA-seq aligner Tophat2 as well as other downstream quantifiaction tools).
Stage the alignment data
First connect to stampede2.tacc.utexas.edu and start an idev session. This should be second nature by now ![]()
...
| File Name | Description | Sample |
|---|---|---|
| Sample_Yeast_L005_R1.cat.fastq.gz | Paired-end Illumina, First of pair, FASTQ | Yeast ChIP-seq |
| Sample_Yeast_L005_R2.cat.fastq.gz | Paired-end Illumina, Second of pair, FASTQ | Yeast ChIP-seq |
| human_rnaseq.fastq.gz | Paired-end Illumina, First of pair only, FASTQ | Human RNA-seq |
| human_mirnaseq.fastq.gz | Single-end Illumina, FASTQ | Human microRNA-seq |
| cholera_rnaseq.fastq.gz | Single-end Illumina, FASTQ | V. cholerae RNA-seq |
Reference Genomes
Before we get to alignment, we need a reference to align to. This is usually an organism's genome, but can also be any set of names sequences, such as a transcriptome or other set of genes.
...
| Tip | |||||
|---|---|---|---|---|---|
The BioITeam maintains a set of reference indexes for many common organisms and aligners. They can be found in aligner-specific sub-directories of the /work2/projects/BioITeam/ref_genome area. E.g.:
|
Exploring FASTA with grep
It is often useful to know what chromosomes/contigs are in a FASTA file before you start an alignment so that you're familiar with the contig naming convention – and to verify that it's the one you expect. For example, chromosome 1 is specified differently in different references and organisms: chr1 (USCS human), chrI (UCSC yeast), or just 1 (Ensembl human GRCh37).
...
| Expand | ||
|---|---|---|
| ||
There are 17 contigs. |
Aligner overview
There are many aligners available, but we will concentrate on two of the most popular general-purpose ones: bwa and bowtie2. The table below outlines the available protocols for them.
| alignment type | aligner options | pro's | con's |
|---|---|---|---|
| global with bwa | SE:
PE:
|
|
|
| global with bowtie2 | bowtie2 --global |
|
|
| local with bwa | bwa mem |
|
|
| local with bowtie2 | bowtie2 --local |
|
|
Exercise #1: BWA global alignment – Yeast ChIP-seq
Overview ChIP-seq alignment workflow with BWA
We will perform a global alignment of the paired-end Yeast ChIP-seq sequences using bwa. This workflow has the following steps:
...
We're going to skip the trimming step for now and see how it goes. We'll perform steps 2 - 5 now and leave samtools for a later exercise since steps 6 - 10 are common to nearly all post-alignment workflows.
Introducing BWA
Like other tools you've worked with so far, you first need to load bwa. Do that now, and then enter bwa with no arguments to view the top-level help page (many NGS tools will provide some help when called with no arguments). Note that bwa is available both from the standard TACC module system and as BioContainers. module.
...
As you can see, bwa include many sub-commands that perform the tasks we are interested in.
Building the BWA sacCer3 index
We will index the genome with the bwa index command. Type bwa index with no arguments to see usage for this sub-command.
...
| Code Block | ||
|---|---|---|
| ||
sacCer3.fa sacCer3.fa.amb sacCer3.fa.ann sacCer3.fa.bwt sacCer3.fa.pac sacCer3.fa.sa |
Performing the bwa alignment
Now, we're ready to execute the actual alignment, with the goal of initially producing a SAM file from the input FASTQ files and reference. First prepare a directory for this exercise and link the sacCer3 reference directories there (this will make our commands more readable).
...
| Expand | ||
|---|---|---|
| ||
Both R1 and R2 reads must have separate alignment records, because there were 1,184,360 R1+R2 reads and the same number of alignment records. The SAM file must contain both mapped and un-mapped reads, because there were 1,184,360 R1+R2 reads and the same number of alignment records. Alignment records occur in the same read-name order as they did in the FASTQ, except that they come in pairs. The R1 read comes 1st, then the corresponding R2. This is called read name ordering. |
Using cut to isolate fields
Recall the format of a SAM alignment record:
...
| Expand | ||
|---|---|---|
| ||
| Recall that these are 100 bp reads and we did not remove adapter contamination. There will be a distribution of fragment sizes – some will be short – and those short fragments may not align without adapter removal (e.g. with fastx_trimmer). |
Exercise #2: Basic SAMtools Utilities
The SAMtools program is a commonly used set of tools that allow a user to manipulate SAM/BAM files in many different ways, ranging from simple tasks (like SAM/BAM format conversion) to more complex functions (like sorting, indexing and statistics gathering). It is available in the TACC module system (as well as in BioContainers). Load that module and see what samtools has to offer:
...
| Warning | ||
|---|---|---|
| ||
There are two main "eras" of SAMtools development:
Unfortunately, some functions with the same name in both version eras have different options and arguments! So be sure you know which version you're using. (The samtools version is usually reported at the top of its usage listing). TACC BioContainers also offers the original samtools version: samtools/ctr-0.1.19--3. |
samtools view
The samtools view utility provides a way of converting between SAM (text) and BAM (binary, compressed) format. It also provides many, many other functions which we will discuss lster. To get a preview, execute samtools view without any other arguments. You should see:
...
| Expand | ||
|---|---|---|
| ||
samtools view -h shows header records along with alignment records. samtools view -H shows header records only. |
samtools sort
Looking at some of the alignment record information (e.g. samtools view yeast_pairedend.bam | cut -f 1-4 | more), you will notice that read names appear in adjacent pairs (for the R1 and R2), in the same order they appeared in the original FASTQ file. Since that means the corresponding mappings are in no particular order, searching through the file very inefficient. samtools sort re-orders entries in the SAM file either by locus (contig name + coordinate position) or by read name.
...
| Expand | ||
|---|---|---|
| ||
The yeast_pairedend.sam text file is the largest at ~348 MB. The name-ordered binary yeast_pairedend.bam text file only about 1/3 that size, ~110 MB. They contain exactly the same records, in the same order, but conversion from text to binary results in a much smaller file. The coordinate-ordered binary yeast_pairedend.sort.bam file is even slightly smaller, ~91 MB. This is because BAM files are actually customized gzip-format files. The customization allows blocks of data (e.g. all alignment records for a contig) to be represented in an even more compact form. You can read more about this in section 4 of the SAM format specification. |
samtools index
Many tools (like IGV, the Integrative Genomics Viewer) only need to use portions of a BAM file at a given point in time. For example, if you are viewing alignments that are within a particular gene, alignment records on other chromosomes do not need to be loaded. In order to speed up access, BAM files are indexed, producing BAI files which allow fast random access. This is especially important when you have many alignment records.
...
| Expand | ||
|---|---|---|
| ||
While the yeast_pairedend.sort.bam text file is ~91 MB, its index (yeast_pairedend.sort.bai) is only 20 KB. |
samtools flagstat
Since the BAM file contains records for both mapped and unmapped reads, just counting records doesn't provide information about the mapping rate of our alignment. The samtools flagstat tool provides a simple analysis of mapping rate based on the the SAM flag fields.
...
| Expand | ||
|---|---|---|
| ||
About 86% of mapped read were properly paired. This is actually a bit on the low side for ChIP-seq alignments which typically over 90%. |
samtools idxstats
More information about the alignment is provided by the samtools idxstats report, which shows how many reads aligned to each contig in your reference. Note that samtools idxstats must be run on a sorted, indexed BAM file.
...
| Tip |
|---|
If you're mapping to a non-genomic reference such as miRBase miRNAs or another set of genes (a transcriptome), samtools idxstats gives you a quick look at quantitative alignment results. |
Exercise #3: PE alignment with BioITeam scripts
Now that you've done everything the hard way, let's see how to do run an alignment pipeline using a BWA alignment script maintained by the BioITeam, /work2/projects/BioITeam/common/script/align_bwa_illumina.sh. Type in the script name to see its usage.
...
- The 1st command performs a paired-end BWA global alignment (similar to above), but asks that the 100 bp reads be trimmed to 50 first.
- we refer to the pre-built index for yeast by name: sacCer3
- this index is located in the /work/projects/BioITeam/ref_genome/bwa/bwtsw/sacCer3/ directory
- we provide the name of the R1 FASTQ file
- because we request a PE alignment (the 1 argument) the script will look for a similarly-named R2 file.
- all output files associated with this command will be named with the prefix bwa_global.
- we refer to the pre-built index for yeast by name: sacCer3
- The 2nd command performs a paired-end BWA local alignment.
- all output files associated with this command will be named with the prefix bwa_local.
- no trimming is requested because the local alignment should ignore 5' and 3' bases that don't match the reference genome
- The 3rd command performs a paired-end Bowtie2 global alignment.
- the Bowtie2 alignment script has the same first arguments as the BWA alignment script.
- all output files associated with this command will be named with the prefix bt2_global.
- again, we specify that reads should first be trimmed to 50 bp.
- The 4th command performs a paired-end Bowtie2 local alignment.
- all output files associated with this command will be named with the prefix bt2_local.
- again, no trimming is requested for the local alignment.
Output files
This alignment pipeline script performs the following steps:
...
- <prefix>.align.log – Log file of the entire alignment process.
- check the tail of this file to make sure the alignment was successful
- <prefix>.sort.dup.bam – Sorted, duplicate-marked alignment file.
- <prefix>.sort.dup.bam.bai – Index for the sorted, duplicate-marked alignment file
- <prefix>.flagstat.txt – samtools flagstat output
- <prefix>.idxstats.txt – samtools idxstats output
- <prefix>.samstats.txt – Summary alignment statistics from Anna's stats script
- <prefix>.iszinfo.txt – Insert size statistics (for paired-end alignments) from Anna's stats script
Verifying alignment success
The alignment log will have a "I ran successfully" message at the end if all went well, and if there was an error, the important information should also be at the end of the log file. So you can use tail to check the status of an alignment. For example:
...
| Code Block | ||
|---|---|---|
| ||
grep -L 'completed successfully' aln_script.cmds |
Checking alignment statistics
The <prefix>.samstats.txt statistics files produced by the alignment pipeline has a lot of good information in one place. If you look at bwa_global.samstats.txt you'll see something like this:
...
| Expand | |||||
|---|---|---|---|---|---|
| |||||
Use grep to isolate the Mode line, and awk to isolate the median value field:
|
TACC batch system considerations
The great thing about pipeline scripts like this is that you can perform alignments on many datasets in parallel at TACC, and they are written to take advantage of having multiple cores on TACC nodes where possible.
...