A wrapper to automate running Trinity on TACC. Parallelizable steps are distributed to multiple nodes, non-parallelizable steps are run on largemem nodes (with 1TB RAM).
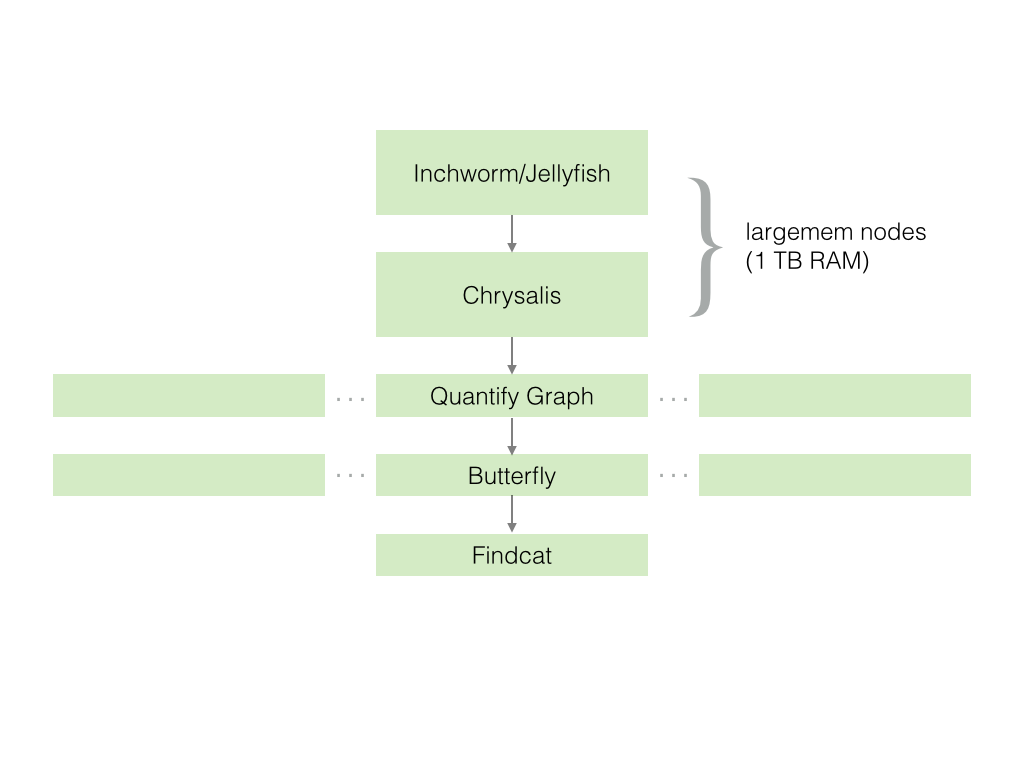
Trinity is a de novo transcriptome assembler. It is implemented as a pipeline with three named steps: Inchworm, Chrysalis and Butterfly. The Inchworm step cuts up in the input read data into kmers (counting them), assembles long contigs based on a greedy kmer overlap algorithm, and performs clustering on the long contigs. Chrysalis takes the clustered contigs (which are putatively for individual genes), and constructs de Bruijn graphs for them. The Butterfly step takes the de Bruijn graphs (one for each putative gene) and traverses them, constructing isoforms based on read support in the graph.
The Inchworm and Chrysalis steps are not parallelizable (all the data needs to be in the same memory space), and require a very large amount of memory. (Actually, the final step of Chrysalis called "QuantifyGraph" is parallelizable, and we'll treat is separately from the earlier Chrysalis steps.) QuantifyGraph and Butterfly are highly parallelizable, and can finish running quickly after being distributed to many nodes. TACC is well-suited to this pipeline, with both high-memory (largemem) and lots of normal nodes available. assemble_trinity is a script that automates running the steps of the Trinity pipeline on TACC. It runs things in parallel when possible on multiple normal nodes, and runs non-parallelizable steps (Inchwork, Chrysalis) on largemem nodes.
Running assemble_trinity takes just one command. The script automatically generates the launcher scripts and submits them for you. There's no need to put assemble_trinity inside a launcher script (in fact, that won't work). To run a plain vanilla Trinity assembly without and special options, run this command at your command prompt:
assemble_trinity -a <your_allocation> -l <R1_reads.fq> -r <R2_reads.fq> -o <output_directory>
For the output directory, we highly recommend giving a simple name (not a full path), as the script currently isn't set up to traverse a full path and generate any necessary subdirectories. It also does something weird with changing slashes to periods, which can hide the output directory. Just use "-o Fish_1" or something. Handling full paths is an issue we may address in the future.
If you want to use Trinity options that assembly_trinity doesn't support yet, you can still use assemble_trinity to generate the list of launchers necessary to submit to TACC, then edit the *.sge files to add your desired options to the assembly. Just add the --no-run option to the assemble_trinity command. This will generate all the launchers, but will not submit them. Make any changes you desire, then submit all the launchers in sequence by simply running submit_launchers submission.list. (The file submission.list is a simple text list of the launcher files, and the submit_launchers script reads the list and submits the jobs in order, with commands to hold each job until the previous finishes.)
As of now (early November), assemble_trinity is only supported on Lonestar. It will probably work on Stampede, but we need to make some changes to take full advantage of Stampede.