Getting to a remote computer
The Terminal window
- Macs and Linux have Terminal programs built-in – find it now on your computer
- Windows needs help
- Putty – http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
- simple Terminal and file copy programs
- download putty.exe (terminal) and pscp.exe (secure copy client)
- Git-bash – http://msysgit.github.io/
- terminal plus minimal Linux environment
- has ssh, scp but not rsync
- terminal plus minimal Linux environment
- Cygwin – http://www.cygwin.com/
- a full Linux environment, including X-windows for running GUI programs remotely
- complicated to install
- Putty – http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
SSH
ssh is an executable program that runs on your local computer and allows you to connect securely to a remote computer.
On Macs, Linux and Windows (Git-bash or Cygwin), you run it from a Terminal window. Answer yes to the SSH security question prompt.
ssh your_TACC_userID@stampede.tacc.utexas.edu
If you're using Putty as your Terminal from Windows:
- Double-click the Putty.exe icon
- In the PuTTY Configuration window
- make sure the Connection type is
SSH - enter stampede.tacc.utexas.edu for Host Name
- click Open button
- answer Yes to the SSH security question
- make sure the Connection type is
- In the PuTTY terminal
- enter your TACC user id after the login as: prompt, then Enter
The bash shell
You're now at a command line! It looks as if you're running directly on the remote computer, but really there are two programs communicating: your local Terminal and the remote Shell. There are many shell programs available in Linux, but the default is bash (Bourne-again shell).
The Terminal is pretty "dumb" – just sending your typing over its secure sockets layer (SSL) connection to TACC, then displaying the text sent back by the shell. The real work is being done on the remote computer, by programs called by the bash shell.

Setting up your environment
First create a few directories and links we will use (more on these later).
You can copy and paste these lines from the code block below into your Terminal window. Just make sure you hit "Enter" after the last line.
Create some symbolic links that will come in handy later:
cd ln -s -f $SCRATCH scratch ln -s -f $WORK work ln -s -f /corral-repl/utexas/BioITeam ln -s -f /work/01063/abattenh/local .local
Set up a $HOME/local/bin directory and link some scripts there that we will use a lot in the class.
If you already have a local sub-directory in your $HOME directory, rename it temporarily. You can restore it after the class is over.
mv local local.beforeNGS
mkdir -p $HOME/local/bin cd $HOME/local/bin ln -s -f /corral-repl/utexas/BioITeam/bin/launcher_creator.py ln -s -f /work/01063/abattenh/local/bin/cutadapt ln -s -f /work/01063/abattenh/local/bin/samstat
Now execute the lines below to set up a login script, called .bashrc
Whenever you login via an interactive shell as you did above, a well-known script is executed by the shell to establish your favorite environment settings. We've set up a common login script for you to start with that will help you know where you are in the file system and make it easier to access some of our shared resources. To it up, do the steps below:
If you already have a .bashrc set up, make a backup copy first.
cd cp .bashrc .bashrc.beforeNGS
You can restore your original login script after this class is over.
cd cp /work/01063/abattenh/seq/code/script/tacc/bashrc.corengs .bashrc chmod 600 .bashrc
Since .bashrc is executed when you login, to ensure it is set up properly you should first log off stampede like this:
exit
Then log back in to stampede.tacc.utexas.edu. This time your .bashrc will be executed and you should see a new shell prompt:
stamp:~$
The great thing about this prompt is that it always tells you where you are, which avoids having to issue the pwd (present working directory) command all the time. Execute these commands to see how the prompt reflects your current directory.
mkdir -p tmp/a/b/c cd tmp/a/b/c # Your prompt should look like this: stamp:~/tmp/a/b/c$
The prompt now tells you you are in the c sub-directory of the b sub-directory of the a sub-directory of the tmp sub-directory of your home directory ( ~ ).
So why don't you see the .bashrc file you copied to your home directory? Because all files starting with a period ("dot files") are hidden by default. To see them add the -a (all) option to ls:
cd ls -a
To see even more detail, including file type and permissions and symbolic link targets, add the -l (long listing) switch:
ls -la
Details about your login script
We list its content to the Terminal with the cat (concatenate files) command that simply reads a file and writes each line of content to standard output (here, your Terminal):
cd cat .bashrc
You'll see the following (you may need to scroll up a bit to see the beginning):
#!/bin/bash
# TACC startup script: ~/.bashrc version 2.1 -- 12/17/2013
# This file is NOT automatically sourced for login shells.
# Your ~/.profile can and should "source" this file.
# Note neither ~/.profile nor ~/.bashrc are sourced automatically
# by bash scripts.
# In a parallel mpi job, this file (~/.bashrc) is sourced on every
# node so it is important that actions here not tax the file system.
# Each nodes' environment during an MPI job has ENVIRONMENT set to
# "BATCH" and the prompt variable PS1 empty.
#################################################################
# Optional Startup Script tracking. Normally DBG_ECHO does nothing
if [ -n "$SHELL_STARTUP_DEBUG" ]; then DBG_ECHO "${DBG_INDENT}~/.bashrc{"; fi
##########
# SECTION 1 -- modules
if [ -z "$__BASHRC_SOURCED__" -a "$ENVIRONMENT" != BATCH ]; then
export __BASHRC_SOURCED__=1
# for NGS course
module load python
module load launcher
fi
##########
# SECTION 2 -- environment variables
if [ -z "$__PERSONAL_PATH__" ]; then
export __PERSONAL_PATH__=1
# for NGS course
export ALLOCATION=UT-2015-05-18
export BI=/corral-repl/utexas/BioITeam
export CLASSDIR="$BI/core_ngs_tools"
export PATH=.:$HOME/local/bin:$PATH
fi
##########
# SECTION 3 -- controlling the prompt
# for NGS course
if [ -n "$PS1" ]; then
PS1='stamp:\w$ '
fi
##########
# SECTION 4 -- Umask and aliases
# for NGS course
umask 002
alias ll="ls -l"
##########
# Optional Startup Script tracking
if [ -n "$SHELL_STARTUP_DEBUG" ]; then DBG_ECHO "${DBG_INDENT}}"; fi
So what does the common login script do? A lot! Let's look at just a few of them.
the "she-bang"
The first line is the "she-bang". It tells the shell what program should execute this file – in this case, bash itself – even though the expression is inside a shell comment (denoted by the # character).
#!/bin/bash
environment variables
The login script also sets an environment variable named BI to point to the shared directory: /corral-repl/utexas/BioITeam, and another environment variable named CLASSDIR to point to the specific sub-directory for our class.
export BI=/corral-repl/utexas/BioITeam export CLASSDIR="$BI/core_ngs_tools"
Environment variables are like variables in a programming language like python or perl (in fact bash is a complete programming language). They have a name (like BI above) and a value (the value for BI is the pathname /corral-repl/utexas/BioITeam).
shell completion
You can use these environment variables to shorten typing, for example, to look at the contents of the shared BioITeam directory as shown below, using the magic Tab key to perform shell completion.
# hit Tab once after typing $BI/ to expand the environment variable
ls $BI/
# now hit Tab twice to see the contents of the directory
ls /corral-repl/utexas/BioITeam/
# now type "co" and hit Tab again
ls /corral-repl/utexas/BioITeam/co
# your command line should now look like this
ls /corral-repl/utexas/BioITeam/core_nge_tools/
# now type "m" and one Tab
ls /corral-repl/utexas/BioITeam/core_nge_tools/m
# now just type one Tab
ls /corral-repl/utexas/BioITeam/core_nge_tools/misc/
# the shell expands as far as it can unambiguously, so your command line should look like this
ls /corral-repl/utexas/BioITeam/core_nge_tools/misc/small
# type a period (".") then hit Tab twice again
# You're narrowing down the choices -- you should see two filenames
ls /corral-repl/utexas/BioITeam/core_nge_tools/misc/small.
# finally, type "f" then hit Tab again. It should complete to this:
ls /corral-repl/utexas/BioITeam/core_ngs_tools/misc/small.fq
Important Tip -- the Tab key is your BFF!
The Tab key is one of your best friends in Linux. Hitting it invokes "shell completion", which is as close to magic as it gets!
- Tab once will expand the current command line contents as far as it can unambiguously.
- if nothing shows up, there is no unambiguous match
- Tab twice will give you a list of everything the shell finds matching the current command line.
- you then decide where to go next
extending the $PATH
When you type a command name the shell has to have some way of finding what program to run. The list of places (directories) where the shell looks is stored in the $PATH environment variable. You can see the entire list of locations by doing this:
echo $PATH
As you can see, there are a lot of locations on the $PATH. That's because when you load modules at TACC (such as the module load lines in the common login script), that mechanism makes the programs available to you by putting their installation directories on your $PATH. We'll learn more about modules shortly.
Here's how the common login script adds your $HOME/local/bin directory to the location list – recall that's where we linked some programs we'll use – along with a special dot character ( . ) that means "here", or "whatever the current directory is".
export PATH=.:$HOME/local/bin:$PATH
setting up the friendly command prompt
The complicated looking if statement in SECTION 3 of your .bashrc sets up a friendly shell prompt that shows the current working directory. This is done by setting the special PS1 environment variable and including a special \w directive that the shell knows means "current directory".
########## # SECTION 3 -- controlling the prompt # for NGS course if [ -n "$PS1" ]; then PS1='stamp:\w$ ' fi
File systems at TACC
The first thing you'll want to do is transfer your sequencing data to TACC so you can process it there. Here is an overview of the different storage areas at TACC, their characteristics, and Linux commands generally used to perform the data transfers.
| TACC storage areas and Linux commands to access data (all commands executed at TACC except laptop-to-TACC copies must be executed on your laptop) |
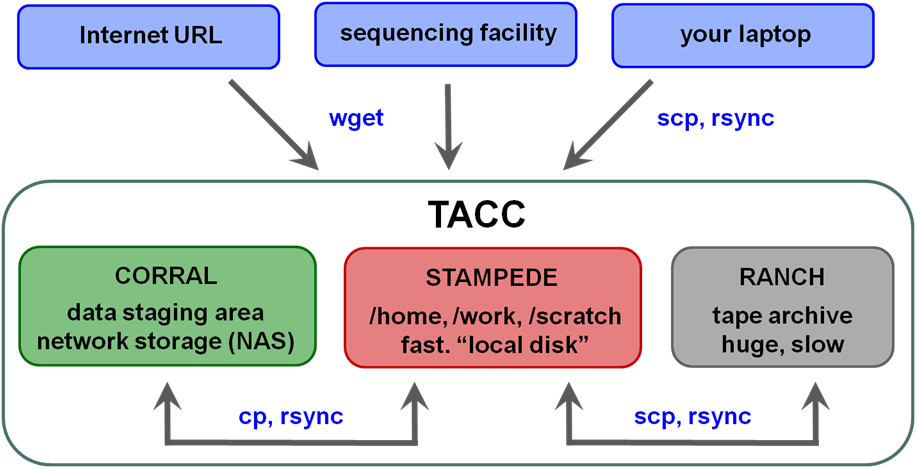 |
Local file systems
There are 3 local file systems available on any TACC compute cluster (stampede, lonestar, etc.), each with different characteristics. All these local file systems are very fast and set up for parallel I/O (Lustre file system).
On stampede these local file systems have the following characteristics:
| Home | Work | Scratch | |
|---|---|---|---|
| quota | 5 GB | 1024 GB = 1 TB | 12+ PB (basically infinite) |
| policy | backed up | not backed up, not purged | not backed up, purged if not accessed recently (~10 days) |
| access command | cd | cdw | cds |
| environment variable | $HOME | $WORK | $SCRATCH |
| root file system | /home | /work | /scratch |
| use for | Small files such as scripts that you don't want to lose. | Medium-sized artifacts you don't want to copy over all the time. For example, custom programs you install (these can get large), or annotation file used for analysis. | Large files accessed from batch jobs. Your starting files will be copied here from somewhere else, and your results files will be copied back to your home system. |
When you first login, the system gives you information about disk quota and your compute allocation quota:
--------------------- Project balances for user abattenh ----------------------- | Name Avail SUs Expires | Name Avail SUs Expires | | CancerGenetics 82105 2015-09-30 | human_brains 45634 2015-06-30 | | UT-2015-05-18 10000 2 015-06-30 | genomeAnalysis 29324 2016-03-31 | ------------------------ Disk quotas for user abattenh ------------------------- | Disk Usage (GB) Limit %Used File Usage Limit %Used | | /home1 0.0 5.0 0.03 178 150000 0.12 | | /work 54.8 1024.0 5.35 2621 3000000 0.09 | -------------------------------------------------------------------------------
changing TACC directories
When you first login, you start in your home directory. Use these commands to change to your other file systems. Notice how your command prompt helpfully changes to show your location.
cdw cds cd
The cd (change directory) command with no arguments takes you to your home directory on any Linux/Unix system. The cdw and cds commands are specific to the TACC environment.
Corral
Corral is a gigantic (multiple PB) storage system (spinning disk) where researchers can store data. UT researchers may request up to 5 TB of corral storage through the normal TACC allocation request process. Additional space on corral can be rented for ~$210/TB/year.
The UT/Austin BioInformatics Team, a loose group of researchers, maintains a common directory area on corral.
ls /corral-repl/utexas/BioITeam
File we will use in this course are in a subdirectory there:
ls /corral-repl/utexas/BioITeam/core_ngs_tools
A couple of things to keep in mind regarding corral:
- corral is a great place to store data in between analyses.
- Copy your data from corral to $SCRATCH
- Run your analysis batch job
- Copy your results back to corral
- On stampede you can access corral directories from login nodes (like the one you're on now), but your batch jobs cannot access corral.
- This is because corral is a network file system, like Samba or NFS.
- Since stampede has so many compute nodes, it doesn't have the network bandwidth that would allow simultaneous access to corral .
- Occasionally corral can become unavailable. This can cause any command to hang that tries to access corral data.
Ranch
Ranch is a gigantic (multiple PB) tape archive system where researchers can archive data. UT researchers may request large (multi-TB) ranch storage allocations through the normal TACC allocation request process.
There is currently no charge for ranch storage. However, since the data is stored on tape it is not immediately available – robots find and mount appropriate tapes when the data is requested, and it can take minutes to hours for the data to appear on disk. (The metadata about your data – the directory structures and file names – is always accessible, but the actual data in the files is not on disk until "staged". See the ranch user guide for more information: https://www.tacc.utexas.edu/user-services/user-guides/ranch-user-guide.
Once that data is staged to the ranch disk it can be copied to other places. However, the ranch file system is not mounted as a local file system from the stampede or lonestar clusters. So remote copy commands are needed to copy data to and from ranch (e.g. scp, sftp, rsync).
Staging your data
So, your sequencing center has some data for you. They will likely send you a list of web or FTP links to use to download the data.
The first task is to get this sequencing data to a permanent storage area. This should not be your laptop or one of the TACC local file systems! Corral is a great place for it, or a server maintained by your lab or company.
We're going to pretend – just for the sake of this class – that your permanent storage area is in your TACC work area. Execute these commands to make your "archive" directory and some sub-directories.
mkdir -p $WORK/archive/original/2015_05.core_ngs
Here's an example of a "best practice". Wherever your permanent storage area is, it should have a rational sub-directory structure that reflects its contents. It's easy to process a few NGS datasets, but when they start multiplying like tribbles, good organization and naming conventions will be the only thing standing between you and utter chaos!
For example:
original– for original sequencing data (compressed fastq files)- subdirectories named by
year_month.<project or purpose>
- subdirectories named by
aligned– for alignment artifacts (bam files, etc)- subdirectories named by
year_month.<project or purpose>
- subdirectories named by
analysis– further downstream analysis- reasonably named subdirectories, often by project
genome– reference genomes and other annotation files used in alignment and analysis- subdirectories for different reference genomes
- e.g.
ucsc/hg19,ucsc/sacCer3,mirbase/v20
code– for scripts and programs you and others in your organization write- ideally maintained in a version control system such as git, subversion or cvs.
- easiest to name sub-directories for people.
Download from a link – wget
Well, you don't have a desktop at TACC to "Save as" to, so what to do with a link? The wget program knows how to access web URLs such as http, https and ftp.
wget
Get ready to run wget from the directory where you want to put the data. Don't press Enter after the wget command – just put a space after it.
cd $WORK/archive/original/2015_05.core_ngs wget
Here are two web links:
- http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/Sample_Yeast_L005_R1.cat.fastq.gz
- http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/Sample_Yeast_L005_R2.cat.fastq.gz
Right click on the 1st link in your browser, then select "Copy link location" from the menu. Now go back to your Terminal. Put your cursor after the space following the wget command then either right-click, or Paste. The command line to be executed should look like this:
wget http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/Sample_Yeast_L005_R1.cat.fastq.gz
Now press Enter to get the command going. Repeat for the 2nd link. Check that you now see the two files (ls).
Copy from a corral location - cp or rsync
Suppose you have a corral allocation where your organization keeps its data, and that the sequencing data has been downloaded there. You can use various Linux commands to copy the data locally from there to your $SCRATCH area.
cp
The cp command copies one or more files from a local source to a local destination. It has the most common form:
cp [options] <source file 1> <source file 2> ... <destination directory>
Make a directory in your scratch area and copy a single file to it. The trailing slash ( / ) on the destination says it is a directory.
mkdir -p $SCRATCH/data/test1 cp /corral-repl/utexas/BioITeam/web/tacc.genomics.modules $SCRATCH/data/test1/ ls $SCRATCH/data/test1
Copy a directory to your scratch area. The -r argument says "recursive".
cds cd data cp -r /corral-repl/utexas/BioITeam/web/general/ general/
Exercise: What files were copied over?
local rsync
The rsync command is typically used to copy whole directories. What's great about rsync is that it only copies what has changed in the source directory. So if you regularly rsync a large directory to TACC, it may take a long time the 1st time, but the 2nd time (say after downloading more sequencing data to the source), only the new files will be copied.
rsync is a very complicated program, with many options (http://rsync.samba.org/ftp/rsync/rsync.html). However, if you use it like this for directories, it's hard to go wrong:
rsync -avrP local/path/to/source_directory/ local/path/to/destination_directory/
The -avrP options say "archive mode" (preserve file modification date/time), verbose, recursive and show Progress. Since these are all single-character options, they can be combined after one option prefix dash ( - ).
The trailing slash ( / ) on the source and destination directories are very important! rsync will create the last directory level for you, but earlier levels must already exist.
cds rsync -avrP /corral-repl/utexas/BioITeam/web/ucsc_custom_tracks/ data/custom_tracks/
Exercise: What files were copied over?
Now repeat the rsync and see the difference:
rsync -avrP /corral-repl/utexas/BioITeam/web/ucsc_custom_tracks/ $SCRATCH/data/custom_tracks/
The bash shell has several convenient "line editing" features:
- use the up arrow to scroll back through the command line history; down arrow goes forward
- use Ctrl-a to move the cursor to the beginning of a line; Ctrl-e to the end
- use Backspace to remove text before the cursor; Delete to remove text after the cursor
Copy from a remote computer - scp or rsync
Provided that the remote computer is running Linux and you have ssh access to it, you can use various Linux commands to copy data over a secure connection.
The good news is that once you have learned cp and local rsync, remote secure copy (scp) and remote rsync are very similar!
scp
The scp command copies one or more files from a source to a destination, where either source or destination can be a remote path.
Remote paths are similar to local paths, but have user and host information first:
user_name@full.host.name:/full/path/to/directory/or/file
-- or –
user_name@host.name:~/path/relative/to/home/directory
Copy a single file to your $SCRATCH/data/test1 directory. We don't really need to access corral remotely, of course, but this shows the remote syntax needed. Be sure to change userid below to your TACC user id!
scp userid@stampede.tacc.utexas.edu:/corral-repl/utexas/BioITeam/web/README.txt $SCRATCH/data/test1 ls $SCRATCH/data/test1
Notes:
- The 1st time you access a new host the SSH security prompt will appear
- You will always be prompted for your remote host password
- The -r recursive argument works for scp also, just like for cp
remote rsync
rsync can be run just like before, but using the remote-host syntax. Here we use two tricks:
- The tilde ( ~ ) at the start of the path means "relative to my home directory"
- We traverse through the BioITeam symbolic link created in your home directory earlier.
- We use the same tilde ( ~ ) in the destination to traverse the scratch symbolic link in your home directory.
Don't forget to change userid below.
rsync -avrP userid@stampede.tacc.utexas.edu:~/BioITeam/web/ucsc_custom_tracks/ ~/scratch/data/custom_tracks/
Exercise: Was anything copied?
Scavenger hunt exercise
Here's a fun scavenger hunt for more practice. Issue the following commands to get practice what you've learned so far:
cd cp -r /corral-repl/utexas/BioITeam/linuxpractice . cd linuxpractice cd what cat readme
Where are you when you're all done?