Before you start the alignment and analysis processes, it us useful to perform some initial quality checks on your raw data. You may also need to pre-process the sequences to trim them or remove adapters. Here we will assume you have paired-end data from GSAF's Illumina HiSeq sequencer.
Setup
Special stampede login
Before we start, log into ls5 like you did yesterday, but use this special hostname:
login5.ls5.tacc.utexas.edu
Normally you should not perform significant computation on login nodes, since they are shared by all users in the TACC community. Well, there are a few exceptions, and login5.ls5.tacc.utexas.edu is one of them. Is it a dedicated login node owned by CSSB and CCBB, so we have given you access to it for the duration of this course. This will let us do a few things at the command line that would normally set off alarm bells from the TACC folks if we all did them on a standard login node.
Data staging
Recall that yesterday we copied some FASTQ data to our "permanent archive area".
Get the yeast data if you haven't already.
mkdir -p $WORK/archive/original/2018_05.core_ngs cd $WORK/archive/original/2018_05.core_ngs wget http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/Sample_Yeast_L005_R1.cat.fastq.gz wget http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/Sample_Yeast_L005_R2.cat.fastq.gz
Let's now set ourselves up to process this data in $SCRATCH, using some of best practices for organizing our workflow.
# Create a $SCRATCH area to work on data for this course, # with a sub-directory for pre-processing raw fastq files mkdir -p $SCRATCH/core_ngs/fastq_prep # Make a symbolic links to the original yeast data in $WORK. cd $SCRATCH/core_ngs/fastq_prep ln -s -f $WORK/archive/original/2018_05.core_ngs/Sample_Yeast_L005_R1.cat.fastq.gz ln -s -f $WORK/archive/original/2018_05.core_ngs/Sample_Yeast_L005_R2.cat.fastq.gz
Illumina sequence data format (FASTQ)
GSAF gives you paired end sequencing data in two matching FASTQ format files, containing reads for each end sequenced. See where your data really is and how big it is.
# the -l options says "long listing" which shows where the link goes, # but doesn't show details of the real file ls -l # the -L option says to follow the link to the real file, -l means long listing (includes size) # and -h says "human readable" (e.g. MB, GB) ls -Llh
4-line FASTQ format
Each read end sequenced is represented by a 4-line entry in the FASTQ file that looks like this:
@HWI-ST1097:127:C0W5VACXX:5:1101:4820:2124 1:N:0:CTCAGA TCTCTAGTTTCGATAGATTGCTGATTTGTTTCCTGGTCATTAGTCTCCGTATTTATATTATTATCCTGAGCATCATTGATGGCTGCAGGAGGAGCATTCTC + CCCFFFFDHHHHHGGGHIJIJJIHHJJJHHIGHHIJFHGICA91CGIGB?9EF9DDBFCGIGGIIIID>DCHGCEDH@C@DC?3AB?@B;AB??;=A>3;;
Line 1 is the unique read name. The format for Illunia reads is as follows, using the read name above:
machine_id:lane:flowcell_grid_coordinates end_number:failed_qc:0:barcode
@HWI-ST1097:127:C0W5VACXX:5:1101:4820:2124 1:N:0:CTCAGA
- The line as a whole will be unique for this read fragment. However, the corresponding R1 and R2 reads will have identical machine_id:lane:flowcell_grid_coordinates information. This common part of the name ties the two read ends together.
- Most sequencing facilities will not give you qc-failed reads (failed_qc = Y) unless you ask for them.
Line 2 is the sequence reported by the machine, starting with the first base of the insert (the 5' adapter has usually been removed by the sequencing facility). These are ACGT or N uppercase characters.
Line 3 is always '+' from GSAF (it can optionally include a sequence description)
Line 4 is a string of Ascii-encoded base quality scores, one character per base in the sequence.
- For each base, an integer Phred-type quality score is calculated as
integer score = -10 log(probabilty base is wrong)then added to 33 to make a number in the Ascii printable character range. - As you can see from the table below, alphabetical letters - good, numbers – ok, most special characters – bad (except :;<=>?@).

See the Wikipedia FASTQ format page for more information.
Exercise: What character in the quality score string in the fastq entry above represents the best base quality? Roughly what is the error probability estimated by the sequencer?
About compressed files
Sequencing data files can be very large - from a few megabytes to gigabytes. And with NGS giving us longer reads and deeper sequencing at decreasing price points, it's not hard to run out of storage space. As a result, most sequencing facilities will give you compressed sequencing data files.
The most common compression program used for individual files is gzip and its counterpart gunzip whose compressed files have the .gz extension. The tar and zip programs are most commonly used for compressing directories.
Let's take a look at the size difference between uncompressed and compressed files. We use the -l option of ls to get a long listing that includes the file size, and -h to have that size displayed in "human readable" form rather than in raw byte sizes.
ls -lh $CORENGS/yeast_stuff/*.fastq ls -lh $CORENGS/yeast_stuff/*.fastq.gz
Pathname wildcarding
The asterisk character ( * ) is a pathname wildcard that matches 0 or more characters.
Read more about pathname wildcards here: Pathname wildcards and special characters
Exercise: About how big are the compressed files? The uncompressed files? About what is the compression factor?
You may be tempted to want to un-compress your sequencing files in order to manipulate them more directly – but resist that temptation! Nearly all modern bioinformatics tools are able to work on .gz files, and there are tools and techniques for working with the contents of compressed files without ever un-compressing them.
gzip and gunzip
With no options, gzip compresses the file you give it in-place. Once all the content has been compressed, the original uncompressed file is removed, leaving only the compressed version (the original file name plus a .gz extension). The gunzip function works in a similar manner, except that its input is a compressed file with a .gz file and produces an uncompressed file without the .gz extension.
# make sure you're in your $SCRATCH/core_ngs/fastq_prep directory cd $SCRATCH/core_ngs/fastq_prep # Copy over a small, uncompressed fastq file cp $CORENGS/misc/small.fq . # check the size, then compress it in-place ls -lh small* gzip small.fq # check the compressed file size ls -lh small* # uncompress it again gunzip small.fq.gz ls -lh small*
Both gzip and gunzip are extremely I/O intensive when run on large files.
While TACC has tremendous compute resources and the Lustre parallel file system is great, it has its limitations. It is not difficult to overwhelm the Lustre file system if you gzip or gunzip more than a few files at a time (as few as 3-4).
The intensity of compression/decompression operations is another reason you should compress your sequencing files once (if they aren't already) then leave them that way.
head and tail, more or less
One of the challenges of dealing with large data files, whether compressed or not, is finding your way around the data – finding and looking at relevant pieces of it. Except for the smallest of files, you can't open them up in a text editor because those programs read the whole file into memory, so will choke on sequencing data files! Instead we use various techniques to look at pieces of the files at a time.
The first technique is the use of pagers – we've already seen this with the more command. Review its use now on our small uncompressed file:
# Use spacebar to advance a page; Ctrl-c to exit more small.fq
Another pager, with additional features, is less. The most useful feature of less is the ability to search – but it still doesn't load the whole file into memory, so searching a really big file can be slow.
Here's a summary of the most common less navigation commands, once the less pager is active. It has tons of other options (try less --help).
- q – quit
- Ctrl-f or space – page forward
- Ctrl-b – page backward
- /<pattern> – search for <pattern> in forward direction
- n – next match
- N – previous match
- ?<pattern> – search for <pattern> in backward direction
- n – previous match going back
- N – next match going forward
If you start less with the -N option, it will display line numbers.
Exercise: What line of small.fq contains the read name with grid coordinates 2316:10009:100563?
head
For a really quick peek at the first few lines of your data, there's nothing like the head command. By default head displays the first 10 lines of data from the file you give it or from its standard input. With an argument -NNN (that is a dash followed by some number), it will show that many lines of data.
# shows 1st 10 lines head small.fq # shows 1st 100 lines -- might want to pipe this to more to see a bit at a time head -100 small.fq | more
piping
So what is that vertical bar ( | ) all about? It is the pipe symbol!
The pipe symbol ( | ) connects one program's standard output to the next program's standard input. The power of the Linux command line is due in no small part to the power of piping. Read more about piping here: Piping. And read more about standard I/O streams here: Standard Streams in Unix/Linux.
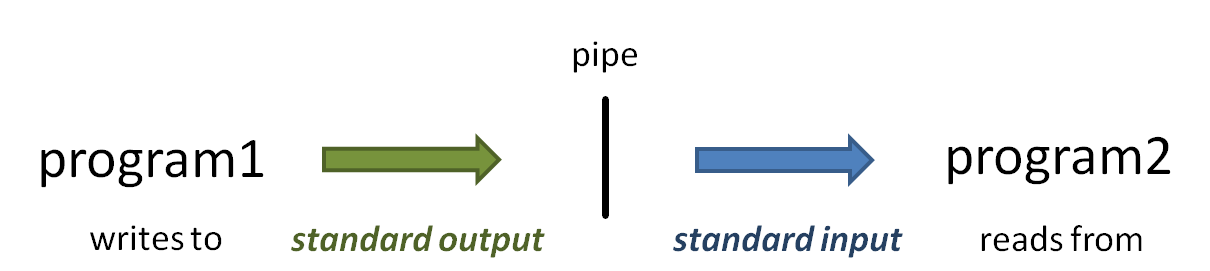
- When you execute the head -100 small.fq | more command, head starts writing lines of the small.fq file to standard output.
- Because of the pipe, the output does not go to the terminal, but is connected to the standard input of the more command.
- Instead of reading lines from a file you specify as a command-line argument, more obtains its input from standard input.
Programs often allow input from standard input
Most Linux commands are designed to accept input from standard input in addition to (or instead of) command line arguments so that data can be piped in.
Many bioinformatics programs also allow data to be piped in. Typically they will require you provide a special argument, such as stdin or -, to tell the program data is coming from standard input instead of a file.
tail
The yang to head's ying is tail, which by default it displays the last 10 lines of its data, and also uses the -NNN syntax to show the last NNN lines. (Note that with very large files it may take a while for tail to start producing output because it has to read through the file sequentially to get to the end.)
But what's really cool about tail is its -n +NNN syntax. This displays all the lines starting at line NNN. Note this syntax: the -n option switch follows by a plus sign ( + ) in front of a number – the plus sign is what says "starting at this line"! Try these examples:
# shows the last 10 lines tail small.fq # shows the last 100 lines -- might want to pipe this to more to see a bit at a time tail -100 small.fq | more # shows all the lines starting at line 900 -- better pipe it to a pager! tail -n +900 small.fq | more # shows 15 lines starting at line 900 because we pipe to head -15 tail -n +900 small.fq | head -15
gunzip -c and zcat tricks
Ok, now you know how to navigate an un-compressed file using head and tail, more or less. But what if your FASTQ file has been compressed by gzip? You don't want to un-compress the file, remember?
So you use the gunzip -c trick. This un-compresses the file, but instead of writing the un-compressed data to another file (without the .gz extension) it write it to its standard output where it can be piped to programs like your friends head and tail, more or less.
Let's illustrate this using one of the compressed files in your fastq_prep sub-directory:
# make sure you're in your $SCRATCH/core_ngs/fastq_prep directory cd $SCRATCH/core_ngs/fastq_prep gunzip -c Sample_Yeast_L005_R1.cat.fastq.gz | more gunzip -c Sample_Yeast_L005_R1.cat.fastq.gz | head gunzip -c Sample_Yeast_L005_R1.cat.fastq.gz | tail gunzip -c Sample_Yeast_L005_R1.cat.fastq.gz | tail -n +900 | head -15 # Note that less will display .gz file contents automatically less Sample_Yeast_L005_R1.cat.fastq.gz
Finally, another command that does the same thing as gunzip -c is zcat – which is like cat except that it works on gzip-compressed (.gz) files!
zcat Sample_Yeast_L005_R1.cat.fastq.gz | more zcat Sample_Yeast_L005_R1.cat.fastq.gz | head zcat Sample_Yeast_L005_R1.cat.fastq.gz | tail zcat Sample_Yeast_L005_R1.cat.fastq.gz | tail -n +900 | head -15
There will be times when you forget to pipe your large zcat or gunzip -c output somewhere – even the experienced among us still make this mistake! This leads to pages and pages of data spewing across your terminal.
If you're lucky you can kill the output with Ctrl-c. But if that doesn't work (and often it doesn't) just close your Terminal window. This terminates the process on the server (like hanging up the phone), then you just can log back in.
Counting your sequences
One of the first thing to check is that your FASTQ files are the same length, and that length is evenly divisible by 4. The wc command (word count) using the -l switch to tell it to count lines, not words, is perfect for this. It's so handy that you'll end up using wc -l a lot to count things. It's especially powerful when used with filename wildcarding.
wc -l small.fq head -100 small.fq > small2.fq wc -l small*.fq
You can also pipe the output of zcat or gunzip -c to wc -l to count lines in your compressed FASTQ file.
Exercise: How many lines are in the Sample_Yeast_L005_R1.cat.fastq.gz file? How many sequences is this?
How to do math on the command line
The bash shell has a really strange syntax for arithmetic: it uses a double-parenthesis operator after the $ sign (which means evaluate this expression). Go figure.
echo $((2368720 / 4))
Here's another trick: backticks evaluation. When you enclose a command expression in backtick quotes ( ` ) the enclosed expression is evaluated and its standard output substituted into the string. (Read more about Quoting in the shell).
Here's how you would combine this math expression with zcat line counting on your file using the magic of backtick evaluation. Notice that the wc -l expression is what is reading from standard input – not echo.
zcat Sample_Yeast_L005_R1.cat.fastq.gz | echo "$((`wc -l` / 4))"
Whew!
bash arithmetic is integer valued only
Note that arithmetic in the bash shell is integer valued only, so don't use it for anything that requires decimal places!
Processing multiple compressed files
You've probably figured out by now that you can't easily use filename wildcarding along with zcat and piping to process multiple files. For this, you need to code a for loop in bash. Fortunately, this is pretty easy. Try this:
for fname in *.gz; do echo "Processing $fname" echo "...$fname has $((`zcat $fname | wc -l` / 4)) sequences" done
Here fname is the name I gave the variable that is assigned a different file generated by the filename wildcard matching, each time through the loop. The actual file is then referenced as $fname inside the loop.
Note the general structure of the for loop. Different portions of the structure can be separated on different lines (like <something> and <something else> below) or put on one line separated with a semicolon ( ; ) like before the do keyword below.
for <variable name> in <expression>; do <something> <something else> done
FASTQ Quality Assurance tools
The first order of business after receiving sequencing data should be to check your data quality. This often-overlooked step helps guide the manner in which you process the data, and can prevent many headaches.
FastQC
FastQC is a tool that produces a quality analysis report on FASTQ files.
Useful links:
- FastQC report for a Good Illumina dataset
- FastQC report for a Bad Illumina dataset
- Online documentation for each FastQC report
First and foremost, the FastQC "Summary" should generally be ignored. Its "grading scale" (green - good, yellow - warning, red - failed) incorporates assumptions for a particular kind of experiment, and is not applicable to most real-world data. Instead, look through the individual reports and evaluate them according to your experiment type.
The FastQC reports I find most useful, and why:
- Should I trim low quality bases?
- consult the Per base sequence quality report
- based on all sequences
- consult the Per base sequence quality report
- Do I need to remove adapter sequences?
- consult the Adapter Content report
- Do I have other contamination?
- consult the Overrepresented Sequences report
- based on the 1st 100,000 sequences, trimmed to 75bp
- consult the Overrepresented Sequences report
- How complex is my library?
- consult the Sequence Duplication Levels report
- but remember that different experiment types are expected to have vastly different duplication profiles
For many of its reports, FastQC analyzes only the first 100,000 sequences in order to keep processing and memory requirements down. Consult the Online documentation for each FastQC report for full details.
Running FastQC
FastQC is available in the TACC module system on ls5. To make it available:
module load fastqc
It has a number of options (see fastqc --help | more) but can be run very simply with just a FASTQ file as its argument.
# make sure you're in your $SCRATCH/core_ngs/fastq_prep directory fastqc small.fq
Exercise: What did FastQC create?
Let's unzip the FastQC .zip file and see what's in it.
unzip small_fastq.zip
What was created?
Looking at FastQC output
You can't run a web browser directly from your "dumb terminal" command line environment. The FastQC results have to be placed where a web browser can access them. One way to do this is to copy the results back to your laptap (read more at Copying files from TACC to your laptop).
For convenience, we put an example FastQC report at this URL: http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/Sample_Yeast_L005_R1.cat_fastqc/fastqc_report.html
Exercise: Based on this FastQC output, should we trim this data?
FASTQ or BAM statistics with samstat
The samstat program can also produce a quality report for FASTQ files, and it can also report on aligned sequences in a BAM file.
Again, this program is not available through the TACC module system but is available in the BioITeam directory and was linked into your ~/local/bin directory. You should be able just to type samstat and see some documentation.
Running samstat on FASTQ files
Here's how you run samstat on a compressed FASTQ files. Let's only run it on a few sequences to avoid overloading the system:
cd $SCRATCH/core_ngs/fastq_prep zcat Sample_Yeast_L005_R1.cat.fastq.gz | head -100000 | samstat -f fastq -n samstat.fastq
This would produce a file named samstat.fastq.html which you need to view in a web browser. The results can be seen here: http://web.corral.tacc.utexas.edu/BioITeam/samstat.fastq.html
And here's some example output from bacterial sequences: http://web.corral.tacc.utexas.edu/BioITeam/SRR030257_1.fastq.html
Running samstat on BAM files
Before running samstat on a BAM file at TACC, you must make the samtools program accessible by load the samtools module.
module load samtools
Here's how you can run samstat on a small BAM file. This produces a file named small.bam.html which you need to view in a web browser.
cd $SCRATCH/core_ngs/fastq_prep cp $CORENGS/misc/small.bam . samstat -F 772 small.bam
Note that odd -F 772 option – it's the filtering flags corresponding to samtools view -F <flags>. The value supplied above is what you should supply when you want to analyze only the reads that mapped in your BAM file (BAM files can contain both mapped and unmapped reads).
You can see the results here: http://web.corral.tacc.utexas.edu/BioITeam/small.bam.html. You can also view sample output for aligned yeast data here: http://web.corral.tacc.utexas.edu/BioITeam/yeast_stuff/yeast_chip_sort.bam.html
Trimming sequences
There are two main reasons you may want to trim your sequences:
- As a quick way to remove 3' adapter contamination, when extra bases provide little additional information
- For example, 75+ bp ChIP-seq reads – 50 bases are more than enough for a good mapping, and trimming to 50 is easier than adapter removal, especially for paired end data.
- You would not choose this approach for RNA-seq data, where 3' bases may map to a different exon, and that is valuable information.
- Instead you would specifically remove adapter sequences.
- Low quality base reads from the sequencer can cause an otherwise mappable sequence not to align
- This is more of an issue with sequencing for genome assembly – both bwa and bowtie2 seem to do fine with a few low quality bases, soft clipping them if necessary.
There are a number of open source tools that can trim off 3' bases and produce a FASTQ file of the trimmed reads to use as input to the alignment program.
FASTX Toolkit
The FASTX Toolkit provides a set of command line tools for manipulating both FASTA and FASTQ files. The available modules are described on their website. They include a fast fastx_trimmer utility for trimming FASTQ sequences (and quality score strings) before alignment.
FASTX Toolkit is available via the TACC module system.
module spider fastx_toolkit module load fastx_toolkit
Here's an example of how to run fastx_trimmer to trim all input sequences down to 50 bases. By default the program reads its input data from standard input and writes trimmed sequences to standard output:
# make sure you're in your $SCRATCH/core_ngs/fastq_prep directory zcat Sample_Yeast_L005_R1.cat.fastq.gz | fastx_trimmer -l 50 -Q 33 > trim50_R1.fq
- The -l 50 option says that base 50 should be the last base (i.e., trim down to 50 bases)
- The -Q 33 option specifies how base qualities on the 4th line of each FASTQ entry are encoded.
- The FASTX Toolkit is an older program written in the time when Illumina base qualities were encoded differently, so its default does not work for modern FASTQ files.
- These days Illumina base qualities follow the Sanger FASTQ standard (Phred score + 33 to make an ASCII character).
Exercise: compressing fastx_trimmer output
How would you tell fastx_trimmer to compress (gzip) its output file?
Exercise: other fastx toolkit programs
What other FASTQ manipulation programs are part of the FASTX Toolkit?
Adapter trimming with cutadapt
Data from RNA-seq or other library prep methods that result in short fragments can cause problems with moderately long (50-100bp) reads, since the 3' end of sequence can be read through to the 3' adapter at a variable position. This 3' adapter contamination can cause the "real" insert sequence not to align because the adapter sequence does not correspond to the bases at the 3' end of the reference genome sequence.
Unlike general fixed-length trimming (e.g. trimming 100 bp sequences to 50 bp), specific adapter trimming removes differing numbers of 3' bases depending on where the adapter sequence is found.
You must tell any adapter trimming program what your R1 and R2 adapters look like.
The GSAF website describes the flavors of Illumina adapter and barcode sequences in more detail: Illumina - all flavors.
The cutadapt program is an excellent tool for removing adapter contamination. The program is not available through TACC's module system but we linked a copy into your $HOME/local/bin directory.
First, make sure cutadapt is working in your environment by asking it for help:
cutadapt --help
If this gets an error, make sure your cutadapt setup is correct as described below.
A common application of cutadapt is to remove adapter contamination from small RNA library sequence data, so that's what we'll show here, assuming GSAF-format small RNA library adapters.
When you run cutadapt you give it the adapter sequence to trim, and this is different for R1 and R2 reads. Here's what the options look like (without running it on our files yet).
cutadapt -m 22 -O 4 -a AGATCGGAAGAGCACACGTCTGAACTCCAGTCAC <fastq_file>
cutadapt -m 22 -O 4 -a TGATCGTCGGACTGTAGAACTCTGAACGTGTAGA <fastq_file>
Notes:
- The -m 22 option says to discard any sequence that is smaller than 22 bases (minimum) after trimming.
- This avoids problems trying to map very short, highly ambiguous sequences.
- the -O 4 (Overlap) option says not to trim 3' adapter sequences unless at least the first 4 bases of the adapter are seen at the 3' end of the read.
- This prevents trimming short 3' sequences that just happen by chance to match the first few adapter sequence bases.
Figuring out which adapter sequence to use when can be tricky. Please refer to Please refer to Illumina - all flavors for Illumina library adapter layout. You may want to read all the "gory details" below later.
Exercise: other cutadapt options
The cutadapt program has many options. Let's explore a few.
How would you tell cutadapt to trim trailing N's?
How would you control the accuracy (error rate) of cutadapt's matching between the adapter sequences and the FASTQ sequences?
Suppose you are processing 100 bp reads with 30 bp adapters. By default, how many mismatches between the adapter and a sequence will be tolerated?
How would you require a more stringent matching (i.e., allowing fewer mismatches)?
cutadapt example
Let's run cutadapt on some real human miRNA data.
First, stage the data we want to use. This data is from a small RNA library where the expected insert size is around 15-25 bp.
cd $SCRATCH/core_ngs/fastq_prep cp $CORENGS/human_stuff/Sample_H54_miRNA_L004_R1.cat.fastq.gz . cp $CORENGS/human_stuff/Sample_H54_miRNA_L005_R1.cat.fastq.gz .
Exercise: How many reads are in these files? Is it single end or paired end data?
Exercise: How long are the reads?
Adapter trimming is a rather slow process, and these are large files. So to start with we're going to create a smaller FASTQ file to work with.
zcat Sample_H54_miRNA_L004_R1.cat.fastq.gz | head -2000 > miRNA_test.fq
Now execute cutadapt like this:
cutadapt -m 20 -a AGATCGGAAGAGCACACGTCTGAACTCCAGTCAC miRNA_test.fq 2> miRNA_test.cuta.log | gzip > miRNA_test.cutadapt.fq.gz
Notes:
- Here's one of those cases where you have to be careful about separating standard output and standard error.
- cutadapt writes its FASTQ output to standard output, and writes summary information to standard error.
- In this command we first redirect standard error to a log file named miRNA_test.cuta.log using the 2> syntax, in order to capture cutadapt diagnostics.
- Then standard output is piped to gzip, whose output is the redirected to a new compressed FASTQ file.
- (Read more about Standard I/O streams)
You should see a miRNA_test.cuta.log log file when the command completes. How many lines does it have?
Take a look at the first 12 lines.
It will look something like this:
This is cutadapt 1.10 with Python 2.7.12 Command line parameters: -m 20 -a AGATCGGAAGAGCACACGTCTGAACTCCAGTCAC miRNA_test.fq Trimming 1 adapter with at most 10.0% errors in single-end mode ... Finished in 0.03 s (60 us/read; 1.00 M reads/minute). === Summary === Total reads processed: 500 Reads with adapters: 492 (98.4%) Reads that were too short: 64 (12.8%) Reads written (passing filters): 436 (87.2%) Total basepairs processed: 50,500 bp Total written (filtered): 10,909 bp (21.6%
Notes:
- The Total reads processed reads line tells you how many sequences were in the original FASTQ file.
- Reads with adapters tells you how many of the reads you gave it had at least part of an adapter sequence that was trimmed.
- Here adapter was found in nearly all (98.4%) of the reads. This makes sense given this is a short (15-25 bp) RNA library.
- The Reads that were too short line tells you how may sequences were filtered out because they were shorter than our minimum length (20) after adapter removal (these may have ben primer dimers).
- Here ~13% of the original sequences were removed, which is reasonable.
- Reads written (passing filters) tells you the total number of reads that were written out by cutadapt
- These are reads that were at least 20 bases long after adapters were removed
paired-end data considerations
Special care must be taken when removing adapters for paired-end FASTQ files.
- For paired-end alignment, aligners want the R1 and R2 fastq files to be in the same name order and be the same length.
- Adapter trimming can remove FASTQ sequences if the trimmed sequence is too short
- but different R1 and R2 reads may be discarded
- this leads to mis-matched R1 and R2 FASTQ files, which can cause problems with aligners like bwa
- Recent versions of cutadapt (one of which you're using) has a protocol for re-syncing the R1 and R2 when the R2 is trimmed.
- See the cutadapt manual for more details (https://cutadapt.readthedocs.org/en/stable/).
running cutadapt in a batch job
Now we're going to run cutadapt on the larger FASTQ files, and also perform paired-end adapter trimming on some yeast paired-end RNA-seq data. First stage the 4 FASTQ files we will work on:
mkdir -p $SCRATCH/core_ngs/cutadapt cd $SCRATCH/core_ngs/cutadapt cp $CORENGS/human_stuff/Sample_H54_miRNA_L004_R1.cat.fastq.gz . cp $CORENGS/human_stuff/Sample_H54_miRNA_L005_R1.cat.fastq.gz . cp $CORENGS/yeast_stuff/Yeast_RNAseq_L002_R1.fastq.gz . cp $CORENGS/yeast_stuff/Yeast_RNAseq_L002_R2.fastq.gz .
Now instead of running cutadapt on the command line, we're going to submit a job to the TACC batch system to perform single-end adapter trimming on the two lanes of miRNA data, and paired-end adapter trimming on the two yeast RNAseq FASTQ files.
Paired end adapter trimming is rather complicated, so instead of trying to do it all in one command line we will use one of the handy BioITeam scripts that handles all the details of paired-end read trimming, including all the environment setup.
Paired-end RNA fastq trimming script
The BioITeam has an a number of useful NGS scripts that can be executed by anyone on ls5. or stampede2. They are located in the /work/projects/BioITeam/common/script/ directory.
The name of the script we want is trim_adapters.sh. Just type the full path of the script with no arguments to see its help information:
/work/projects/BioITeam/common/script/trim_adapters.sh
You should see something like this:
trim_adapters.sh 2017_09_08
Trim adapters from single- or paired-end sequences using cutadapt. Usage:
trim_adapters.sh <in_fq> <out_pfx> [ paired min_len adapter1 adapter2 ]
Required arguments:
in_fq For single-end alignments, path to input fastq file.
For paired-end alignemtts, path to the the R1 fastq file
which must contain the string 'R1' in its name. The
corresponding 'R2' must have the same path except for 'R1'
out_pfx Desired prefix of output files.
Optional arguments:
paired 0 = single end alignment (default); 1 = paired end.
min_len Minimum sequence length after adapter removal. Default 32.
adapter1 3' adapter. Default GATCGGAAGAGCACACGTCTGAACTCCAGTCAC
adapter2 5' adapter. Default TGATCGTCGGACTGTAGAACTCTGAACGTGTAGA
Environment variables:
show_only 1 = only show what would be done (default not set)
keep 1 = keep intermediate file(s) (default 0, don't keep)
cuta_args other cutadapt options (e.g. '--trim-n --max-n=0.25')
Examples:
trim_adapters.sh my.fastq.gz h54_totrna_b1 1 40 '' '' '-O 5'
Based on this information, here are the 3 cutadapt commands we want to execute:
/work/projects/BioITeam/common/script/trim_adapters.sh Sample_H54_miRNA_L004_R1.cat.fastq.gz H54_miRNA_L004 0 20 /work/projects/BioITeam/common/script/trim_adapters.sh Sample_H54_miRNA_L005_R1.cat.fastq.gz H54_miRNA_L005 0 20 /work/projects/BioITeam/common/script/trim_adapters.sh Yeast_RNAseq_L002_R1.fastq.gz yeast_rnaseq 1
Let's put these command into a cuta.cmds commands file. But first we need to learn a bit about Editing files in Linux.
Exercise: Create cuta.cmds file
Use nano to create a cuta.cmds file with the 3 cutadapt processing commands above. If you have trouble with this, you can copy a pre-made commands file:
cd $SCRATCH/core_ngs/cutadapt cp $CORENGS/tacc/cuta.cmds .
When you're finished you should have a cuta.cmds file that is 3 lines long (check this with wc -l).
Next create a batch submission script for your job and submit it to the normal queue with a maximum run time of 2 hours.
launcher_maker.py -n cuta.cmds -w 3 -t 2 sbatch --reservation=CCBB_5.22.18AM cuta.slurm showq -u
How will you know your job is done?
You should see several log files when the job is finished:
- H54_miRNA_L004.cuta.log, H54_miRNA_L005.cuta.log, yeast_rnaseq.cuta.log
- these are the main execution log files, one for each trim_adapters.sh command
- H54_miRNA_L004.acut.pass0.log, H54_miRNA_L005.acut.pass0.log
- these are cutadapt statistics files for the single-end adapter trimming
- their contents will look like our small example above
- yeast_rnaseq.acut.pass1.log, yeast_rnaseq.acut.pass2.log
- these are cutadapt statistics files from trimming the R1 and R2 adapters, respectively.
Take a look at the first 13 lines of the yeast_rnaseq.acut.pass1.log log file:
It will look something like this:
This is cutadapt 1.10 with Python 2.7.12 Command line parameters: -m 32 -a GATCGGAAGAGCACACGTCTGAACTCCAGTCAC --paired-output yeast_rnaseq_R2.tmp.cuta.fastq -o yeast_rnaseq_R1.tmp.cuta.fastq Yeast_RNAseq_L002_R1.fastq.gz Yeast_RNAseq_L002_R2.fastq.gz Trimming 1 adapter with at most 10.0% errors in paired-end legacy mode ... Finished in 126.05 s (20 us/read; 3.07 M reads/minute). === Summary === Total read pairs processed: 6,440,847 Read 1 with adapter: 3,875,741 (60.2%) Read 2 with adapter: 0 (0.0%) Pairs that were too short: 112,845 (1.8%) Pairs written (passing filters): 6,328,002 (98.2%)
- cutadapt started with 6,440,847 read pairs
- 112,845 reads were discarded as too short after the R1 adapter was removed
- the same 112,845 reads were discarded from both the R1 and R2 files
- the remaining 6,328,002 were then subjected to pass2 processing.
- 112,845 reads were discarded as too short after the R1 adapter was removed
The resulting pass2 log looks like this:
ls5:/scratch/01063/abattenh/core_ngs/cutadapt$ head -13 yeast_rnaseq.acut.pass2.log This is cutadapt 1.10 with Python 2.7.12 Command line parameters: -m 32 -a TGATCGTCGGACTGTAGAACTCTGAACGTGTAGA --paired-output yeast_rnaseq_R1.cuta.fastq -o yeast_rnaseq_R2.cuta.fastq yeast_rnaseq_R2.tmp.cuta.fastq yeast_rnaseq_R1.tmp.cuta.fastq Trimming 1 adapter with at most 10.0% errors in paired-end legacy mode ... Finished in 97.40 s (15 us/read; 3.90 M reads/minute). === Summary === Total read pairs processed: 6,328,002 Read 1 with adapter: 90,848 (1.4%) Read 2 with adapter: 0 (0.0%) Pairs that were too short: 0 (0.0%) Pairs written (passing filters): 6,328,002 (100.0%)
- cutadapt started with 6,328,002 pass1 reads
- no additional reads were discarded as too short after the R2 adapter was removed
- so new R1 and R2 files, both with 6,328,002 reads, were produced
- yeast_rnaseq_R1.cuta.fastq.gz and yeast_rnaseq_R2.cuta.fastq.gz
Exercise: Verify that both adapter-trimmed yeast_rnaseq fastq files have 6,328,002 reads