Reservations
Our TACC allocation/project for this class is UT-2015-05-18. Use our summer school reservation when submitting batch jobs to get higher priority on the Lonestar5 normal queue during this course:
sbatch --reservation=CCBB <batch_file>.slurm
Compute cluster overview
When you SSH into ls5, your session is assigned to one of a small set of login nodes (also called head nodes). These are not the compute nodes that will run your jobs.
Think of a node as a computer, like your laptop, but probably with more cores and memory. Now multiply that computer a thousand or more, and you have a cluster.
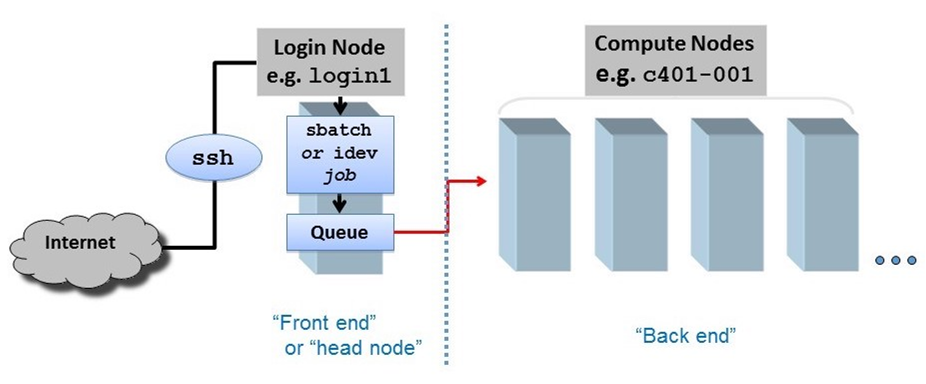
The small set of login nodes are a shared resource (type the users command to see everyone currently logged in) and are not meant for running interactive programs – for that you submit a description of what you want done to a batch system, which farms the work out to one or more compute nodes.
On the other hand, the login nodes are intended for copying files to and from TACC, so they have a lot of network bandwidth while compute nodes have limited network bandwidth.
So follow these guidelines:
- Do not perform substantial computation on the login nodes.
- They are closely monitored, and you will get warnings from the TACC admin folks!
- Code is usually developed and tested somewhere other than TACC, and only moved over when pretty solid.
- Do not perform significant network access from your batch jobs.
- Instead, stage your data onto $SCRATCH from a login node before submitting your job.
Lonestar5 and Stampede2 overview and comparison
Here is a comparison of the configurations and ls5 and stampede2. As you can see, stampede2 is the larger cluster, just recently launched in 2017.
| ls5 | stampede2 | |
|---|---|---|
| login nodes | 6 20 cores each | 6 28 cores each |
| standard compute nodes | 1,252 24 cores per node (48 virtual) | 4,200 KNL (Knights Landing)
1,736 SKX (Skylake)
|
| large memory nodes | 10 total 2 w/1 TB memory, 48 cores | Coming in 2018 |
| batch system | SLURM | SLURM |
| maximum job run time | 48 hours | 96 hours on KNL nodes 48 hours on SKX nodes |
Note the use of the term virtual core above. Compute cores are standalone processors – mini CPUs, each of which can execute separate sets of instructions. However modern cores may also have hyperthreading enabled, where a single core can appear as more than one virtual processor to the Operating system (see https://en.wikipedia.org/wiki/Hyper-threading for more on hyperthreading). For example, Lonestar5 nodes have 2 hyperthreads (HTs) per core, so they actually physically have only 24 cores per node, each of which has 2 HTs for a total of 48 virtual cores.
User guides for ls5 and stampede2 can be found at:
- https://portal.tacc.utexas.edu/user-guides/stampede2
- https://portal.tacc.utexas.edu/user-guides/lonestar5
Unfortunately, the TACC user guides are aimed towards a different user community – the weather modelers and aerodynamic flow simulators who need very fast matrix manipulation and other high performance computing (HPC) features. The usage patterns for bioinformatics – generally running 3rd party tools on many different datasets – is rather a special case for HPC.
Software at TACC
Programs and your $PATH
When you type in the name of an arbitrary progam (ls for example), how does the shell know where to find that program? The answer is your $PATH. $PATH is a pre-defined environment variable whose value is a list of directories.The shell looks for program names in that list, in the order the directories appear.
To determine where the shell will find a particular program, use the which command:
which rsync which cat
The module system
The module system is an incredibly powerful way to have literally thousands of software packages available, some of which are incompatible with each other, without causing complete havoc. The TACC staff builds the desired package from source code in well-known locations that are NOT on your $PATH. Then, when a module is loaded, its binaries are added to your $PATH.
For example, the following module load command makes the bwa aligner available to you:
# first type "bwa" to show that it is not present in your environment: bwa # it's not on your $PATH either: which bwa # now add bwa to your environment and try again: module load bwa bwa # and see how it's now on your $PATH: which bwa # you can see the new directory at the front of $PATH echo $PATH # to remove it, use "unload" module unload bwa bwa # gone from $PATH again... which bwa
module spider
These days the TACC module system includes hundreds of useful bioinformatics programs. To see if your favorite software package has been installed at TACC, use module spider:
module spider samtools module spider tophat module spider bedtools module spider GATK
installing custom software
Even with all the tools available at TACC, inevitably you'll need something they don't have. In this case you can build the tool yourself and install it in a local TACC directory. While building 3rd party tools is beyond the scope of this course, it's really not that hard. The trick is keeping it all organized.
For one thing, remember that your $HOME directory quota is fairly small (10 GB on ls5), and that can fill up quickly if you install many programs. We recommend creating an installation area in your $WORK directory and installing programs there. You can then make symbolic links to the binaries you need in your $HOME/local/bin directory (which was added to your $PATH in your .bashrc).
See how we used a similar trick to make the launcher_maker.py program available to you. Using the ls -l option shows you where symbolic links point to:
ls -l ~/local/bin
$PATH caveat
Remember that the order of locations in the $PATH environment variable is the order in which the locations will be searched. In particular, the module load command adds to the front of your path. This can mask similarly-named programs, for example, in your $HOME/local/bin directory.
Job Execution
Job execution is controlled by the SLURM batch system on both ls5 and stampede2.
To run a job you prepare 2 files:
- a commands file file containing the commands to run, one command per line (<job_name>.cmds)
- a job control file that describes how to run the job (<job_name>.slurm)
The process of running the job involves these steps:
- Create a commands file containing exactly one command per line.
- Prepare a job control file for the commands file that describes how the job should be run.
- You submit the job control file to the batch system. The job is then said to be queued to run.
- The batch system prioritizes the job based on the number of compute nodes needed and the job run time requested.
- When compute nodes become available, the job tasks (command lines in the <job_name>.cmds file) are assigned to one or more compute nodes and begin to run in parallel.
- The job completes when either:
- you cancel the job manually
- all tasks in the job complete (successfully or not!)
- the requested job run time has expired
SLURM at a glance
Here are the main components of the SLURM batch system.
| ls5, stampede2 | |
|---|---|
| batch system | SLURM |
| batch control file name | <job_name>.slurm |
| job submission command | sbatch <job_name>.slurm |
| job monitoring command | showq -u |
| job stop command | scancel -n <job name> |
Simple example
Let's go through a simple example. Execute the following commands to copy a pre-made simple.cmds commands file:
mkdir -p $SCRATCH/core_ngs/slurm/simple cd $SCRATCH/core_ngs/slurm/simple cp $CORENGS/tacc/simple.cmds .
What are the tasks we want to do? Each task corresponds to one line in the simple.cmds file, so let's take a look at it using the cat (concatenate) command that simply reads a file and writes each line of content to standard output (here, your Terminal):
cat simple.cmds
The tasks we want to perform look like this:
echo "Command 1 on `hostname` - `date`" > cmd1.log 2>&1 echo "Command 2 on `hostname` - `date`" > cmd2.log 2>&1 echo "Command 3 on `hostname` - `date`" > cmd3.log 2>&1 echo "Command 4 on `hostname` - `date`" > cmd4.log 2>&1 echo "Command 5 on `hostname` - `date`" > cmd5.log 2>&1 echo "Command 6 on `hostname` - `date`" > cmd6.log 2>&1 echo "Command 7 on `hostname` - `date`" > cmd7.log 2>&1 echo "Command 8 on `hostname` - `date`" > cmd8.log 2>&1
There are 8 tasks. Each is a simple echo command that just outputs string containing the task number and date to a different file.
Use the handy launcher_maker.py program to create the job submission script.
launcher_maker.py -n simple.cmds -t 0:05 -w 8 -v -a UT-2015-05-18 -q dev
You should see output something like the following, and you should see a simple.slurm batch submission file in the current directory.
launcher_maker.py (2016.02.21) Job Parameters for ls5 on slurm: Project: simple Job file: simple.cmds Batch file: simple.slurm (launcher v3) Directory: /scratch/01063/abattenh/core_ngs/simple Queue: development Time: 00:05:00 No job notification email Allocation: UT-2015-05-18 Job file has 8 command lines Commands per node (wayness): 8 Total nodes: 1 Total cores: 24 Modules: Depends on jobid: None Type "sbatch simple.slurm" to queue your job
Submit your batch job like this, then check the batch queue to see the job's status.
sbatch simple.slurm showq -u
If you're quick, you'll see a queue status something like this:
SUMMARY OF JOBS FOR USER: <abattenh> ACTIVE JOBS-------------------- JOBID JOBNAME USERNAME STATE CORE REMAINING STARTTIME ================================================================================ 1578594 simple abattenh Running 48 0:04:52 Thu May 17 00:05:05 WAITING JOBS------------------------ JOBID JOBNAME USERNAME STATE CORE WCLIMIT QUEUETIME ================================================================================ Total Jobs: 1 Active Jobs: 1 Idle Jobs: 0 Blocked Jobs: 0
Notice in my queue status, where the STATE is Running, there are 48 COREs assigned. Why is this, since there were only 8 tasks?
The answer is that the batch jobs cannot share a node – every job, no matter how few tasks requested, will be assigned at least one node. And ls5 nodes have 48 virtual cores each. So the number of cores used will always be an even multiple of 48.
If you don't see your simple job in either the ACTIVE or WAITING sections of your queue, it probably already finished – it should only run for a second or two!
Exercise: What files were created by your job?
filename wildcarding
Here's a cute trick for viewing the contents all your output files at once, using the cat command and filename wildcarding.
cat cmd*.log
The cat command actually takes a list of one or more files (if you're giving it files rather than standard input – more on this shortly) and outputs the concatenation of them to standard output. The asterisk ( * ) in cmd*.log is a multi-character wildcard that matches any filename starting with cmd then ending with .log. So it would match cmd_hello_world.log. You can also specify single-character matches inside brackets ( [ ] ) in either of these ways, this time using the ls command so you can better see what is matching:
ls cmd[12345678].log ls cmd[1-8].log
This technique is sometimes called filename globbing, and the pattern a glob. Don't ask me why – it's a Unix thing. Globbing – translating a glob pattern into a list of files – is one of the handy thing the bash shell does for you. (Read more about Wildcards and special filenames)
Exercise: How would you list all files starting with simple?
Here's what my cat output looks like. Notice the times are all the same, because all the tasks ran in parallel. That's the power of cluster computing!
Command 1 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 2 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 3 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 4 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 5 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 6 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 7 on nid00008 - Thu May 17 00:05:13 CDT 2018 Command 8 on nid00008 - Thu May 17 00:05:13 CDT 2018
echo
Lets take a closer look at a typical task in the simple.cmds file.
echo "Command 3 `date`" > cmd3.log 2>&1
The echo command is like a print statement in the bash shell. Echo takes its arguments and writes them to one line of standard output. While not always required, it is a good idea to put the output string in double quotes.
backtick evaluation
So what is this funny looking `date` bit doing? Well, date is just another Linux command (try just typing it in). Here we don't want the shell to put the string "date" in the output, we want it to execute the date command and put that result into the output. The backquotes ( ` ` also called backticks) around the date command tell the shell we want that command executed and its output substituted into the string. (Read more about Quoting in the shell.)
# These are equivalent: date echo `date` # But different from this: echo date
output redirection
There's still more to learn from one of our simple tasks, something called output redirection:
echo "Command 3 `date`" > cmd3.log 2>&1
Normally echo writes its string to standard output. If you invoke echo in an interactive shell like Terminal, standard output is displayed to the Terminal window.

Usually we want to separate the outputs of all our commands. Why is this important? Suppose we run a job with 100 commands, each one a whole pipeline (alignment, for example). 88 finish fine but 12 do not. Just try figuring out which ones had the errors, and where the errors occurred, if all the output is in one intermingled file and all the error in another intermingled file!
So in the above example the first '>' says to redirect the standard output of the echo command to the cmd3.log file. The '2>&1' part says to redirect standard error to the same place. Technically, it says to redirect standard error (built-in Linux stream 2) to the same place as standard output (built-in Linux stream 1); and since standard output is going to cmd3.log, any standard error will go there also. (Read more about Standard I/O streams.)
So what happens when output is generated by tasks in a batch job? Well, you may have noticed the file winh a name like simple.1578594.joblog was created by your job. It contains all standard output and standard error, generated by your tasks that was not redirected elsewhere.
Job parameters
Now that we've executed a really simple job, let's take a look at some important job submission parameters. These correspond to arguments to the launcher_maker.py script.
A bit of background. Historically, TACC was set up to cater to researchers writing their own C or Fortran codes highly optimized to exploit parallelism (the HPC crowd). Much of TACC's documentation is aimed at this audience, which makes it difficult to pick out the important parts for us.
The kind of jobs we biologists generally run are relatively new to TACC. They even have special names for them: "parametric serial jobs" or "parametric sweeps", by which they mean the same program running on different data sets.
In fact there is a special software module required to run our jobs, called the launcher module. You don't need to worry about activating the launcher module; that's done by the <job_name>.slurm script created by launcher_maker.py like this:
module load launcher
The launcher module knows how to interpret various job parameters in the <job_name>.slurm batch SLURM submission script and use them to create your job and assign its tasks to compute nodes. Our launcher_maker.py program is a simple Python script that lets you specify job parameters and writes out a valid <job_name>.slurm submission script.
launcher_maker.py
If you call launcher_maker.py --help it gives you its usage description:
usage: launcher_maker.py [-h] [-n NAME] [-t TIME] [-w {1,2,3,4,6,8,12,24}]
[-q {normal,dev,largemem,serial}] [-j JOB]
[-l LAUNCHER] [-m MODULES] [-b BASH_COMMANDS]
[-e EMAIL] [-d DEPENDS] [-a ALLOCATION] [-v] [-V]
optional arguments:
-h, --help show this help message and exit
-n NAME Job name (required). Usually the name of your commands
file (with or without .cmds suffix)
-t TIME Maximum job run time. Default="02:00:00" (2 hrs).
Format: [h]h (-t 6 =6 hrs) or [h]h:mm (-t 12:30 =12 hr
30 min) or [h]h:mm:ss (-t 0:30 =30 min)"
-w {1,2,3,4,6,8,12,24}
Wayness: the number of commands to give each node.
Default=24.
-q {normal,dev,largemem,serial}
TACC queue for job submission. Default=normal.
-j JOB Name of the job file containing commands.
Default="<name>.cmds"
-l LAUNCHER Name of the launcher script to be created.
Default="<name>.slurm"
-m MODULES Comma-separated list of module names to load. Example:
"bwa,samtools".
-b BASH_COMMANDS String of Bash commands to execute before the job
starts (enclose in single quotes).
-e EMAIL Email address for job start/end notification. Can also
be specified in SEND_EMAIL environment variable.
-a ALLOCATION TACC allocation for job submission. Use this ONLY if
you have multiple projects. Can be specified in
ALLOCATION environment variable.
-v, --verbose If present, echoes key submission info to stdout.
-V, --version If present, prints program version then exits.
Because it is a long help message, we may want to pipe the output to more, a pager that displays one screen of text at a time. Type the spacebar to advance to the next page, and Ctrl-c to exit from more.
# Use spacebar to page forward; Ctrl-c to exit launcher_maker.py -h | more
launcher_maker.py and the older launcher_creator.py are both BioITeam programs that create batch submission scripts. They are quite similar in may ways, but also reflect the preferences of their two authors (Anna & Benni).
We're using launcher_maker.py in this class because Anna developed it, and because she and Benni don't alwasy agree about programming approaches. This is not an uncommon phenomenon in the world of software development ![]()
job name and commands file
Recall how the simple.slurm batch file was created:
launcher_maker.py -n simple.cmds -t 0:05 -w 8 -v -a UT-2015-05-18 -q dev
- The name of your commands file is given with the -n <job_name>.cmds argument.
- The <job_name> prefix (here simple) is the job name you will see in your queue.
- By default a corresponding <job_name>.slurm batch file is created for you.
- It contains the name of the commands file that the batch system will execute.
queues and runtime
TACC resources are partitioned into queues: a named set of compute nodes with different characteristics. The major ones on ls5 are listed below. Generally you use development (-q dev) when you are writing and testing your code, then normal once you're sure your commands will execute properly.
| queue name | maximum runtime | purpose |
|---|---|---|
| development | 2 hrs | development (short queue wait times) |
| normal | 48 hrs | normal priority (queue waits can sometimes be long) |
| largemem | 48 hrs | large memory jobs |
- In launcher_maker.py, the queue is specified by the -q argument.
- The default queue is normal. Specify -q dev for development queue jobs.
- The maximum runtime you are requesting for your job is specified by the -t argument.
- Format is hh:mm:ss
- Note that your job will be terminated without warning at the end of its time limit!
allocation and SUs
You may be a member of a number of different projects, hence have a choice which allocation to run your job under.
- You specify that allocation name with the -a argument of launcher_maker.py.
- If you have set an $ALLOCATION environment variable to an allocation name, it will be used if you are a member of only one TACC Project.
- When you run a batch job, your project allocation gets "charged" for the time your job runs, in the currency of SUs (System Units).
- For most queues, 1 SU = 1 node/hour of compute time (large memory queues may charge more).
Jobs tasks should have similar expected runtimes
Jobs should consist of tasks that will run for approximately the same length of time. This is because the total node hours for your job is calculated as the run time for your longest running task (the one that finishes last).
For example, if you specify 64 commands and 99 finish in 2 seconds but one runs for 24 hours, you'll be charged for 64 x 24 SUs (node hours) even though the total amount of work performed was only ~24 hours.
wayness (tasks per node)
One of the most confusing things in job submission is the parameter called wayness, which controls how many tasks are run on each computer node.
- Recall that there are 48 virtual cores and 64 GB of memory on each compute node
- so technically you can run up to 48 commands on a node, each with ~1.3 GB available memory
- you can run fewer tasks, and if you do, each task gets more resources
- Because bioinformatics programs generally require more memory and fewer cores, launcher_maker.py sets a 24 cores/node maximum.
| tasks per node (wayness) | cores available to each task | memory available to each task |
|---|---|---|
| 1 | 24 | 64 GB |
| 2 | 12 | 32 GB |
| 3 | 8 | 21.3 GB |
| 4 | 6 | 16 GB |
| 6 | 4 | 10.6 GB |
| 8 | 3 | 8 GB |
| 12 | 2 | 5.3 GB |
| 24 | 1 | 2.6 GB |
- In launcher_maker.py, wayness is specified by the -w argument.
- the default is 24 (one task per core)
- A special case is when you have only 1 command in your job.
- In that case, it doesn't matter what wayness you request.
- Your job will run on one compute node, and have all 48 cores available.
Your choice of the wayness parameter will depend on the nature of the work you are performing: its computational intensity, its memory requirements and its ability to take advantage of multi-processing/multi-threading (e.g. bwa -t option or tophat -p option).
Wayness example
Let's use launcher_maker.py to explore wayness options. First copy over the wayness.cmds commands file:
mkdir -p $SCRATCH/core_ngs/slurm/wayness cd $SCRATCH/core_ngs/slurm/wayness cp $CORENGS/tacc/wayness.cmds .
The wayness.cmds commands file consists of 24 identical lines that look like this:
sleep 3; echo "Command $LAUNCHER_JID of $LAUNCHER_NJOBS ($LAUNCHER_PPN per node) ran on node `hostname` core $LAUNCHER_TSK_ID." > cmd.$LAUNCHER_JID.log 2>&1
Create the batch submission script specifying a wayness of 8 (8 tasks per node), then submit the job and monitor the queue:
launcher_maker.py -n wayness.cmds -w 8 -t 0:10 -v -a UT-2015-05-18 -q dev sbatch wayness.slurm showq -u
Exercise: With 24 tasks requested and wayness of 8, how many nodes will this job require? How much memory will be allocated to each task?
Exercise: If you specified a wayness of 2, how many nodes would this job require? How much memory could each task use?
Look at the output file contents once the job is done.
cat cmd*log # or, for a listing ordered by command number (the 2nd field, a number) cat cmd*log | sort -k 2,2n
You should see something like output below.
Command 1 of 24 (8 per node) ran on node nid00023 core 21. Command 2 of 24 (8 per node) ran on node nid00023 core 19. Command 3 of 24 (8 per node) ran on node nid00023 core 17. Command 4 of 24 (8 per node) ran on node nid00023 core 18. Command 5 of 24 (8 per node) ran on node nid00023 core 16. Command 6 of 24 (8 per node) ran on node nid00023 core 22. Command 7 of 24 (8 per node) ran on node nid00023 core 20. Command 8 of 24 (8 per node) ran on node nid00023 core 23. Command 9 of 24 (8 per node) ran on node nid00022 core 14. Command 10 of 24 (8 per node) ran on node nid00022 core 10. Command 11 of 24 (8 per node) ran on node nid00022 core 12. Command 12 of 24 (8 per node) ran on node nid00022 core 15. Command 13 of 24 (8 per node) ran on node nid00022 core 13. Command 14 of 24 (8 per node) ran on node nid00022 core 11. Command 15 of 24 (8 per node) ran on node nid00022 core 8. Command 16 of 24 (8 per node) ran on node nid00022 core 9. Command 17 of 24 (8 per node) ran on node nid00021 core 4. Command 18 of 24 (8 per node) ran on node nid00021 core 2. Command 19 of 24 (8 per node) ran on node nid00021 core 5. Command 20 of 24 (8 per node) ran on node nid00021 core 0. Command 21 of 24 (8 per node) ran on node nid00021 core 3. Command 22 of 24 (8 per node) ran on node nid00021 core 1. Command 23 of 24 (8 per node) ran on node nid00021 core 6. Command 24 of 24 (8 per node) ran on node nid00021 core 7.
Notice that there are 3 different host names, each of which ran 8 tasks:
cat cmd*log | awk '{print $11}' | sort | uniq -c
should produce this output (read more about piping commands to make a histogram)
8 nid00021
8 nid00022
8 nid00023
Some best practices
Redirect task output and error streams
We've already touched on the need to redirect standard output and standard error for each task. Just remember that funny redirection syntax:
my_program input_file1 output_file1 > file1.log 2>&1
Combine serial workflows into scripts
Another really good way to work is to "bundle" a complex set of steps into a shell script that sets up its own environment, loads its own modules, then executes a series of program steps. You can then just call that script, probably with data-specific arguments, in your commands file. This multi-program script is sometimes termed a pipeline, although complex pipelines may involve several such scripts.
For example, you might have a script called align_bwa.sh (a bash script) or align_bowtie2.py (written in python) that performs multiple steps needed during the alignment process:
- quality checking the input FASTQ file
- trimming or removing adapters from the sequences
- performing the alignment step(s) to create a BAM file
- sort the BAM file
- index the BAM file
- gather alignment statistics from the BAM file
The BioITeam maintains a set of such scripts in the /work/projects/BioITeam/common/script directory. Take a look at some of them after you feel more comfortable with initial NGS processing steps. They can be executed by anyone with a TACC account.
Use one directory per job
You may have noticed that all the files involved in our job were in one directory – the batch submissions file, commands file, log files our tasks wrote, and the launcher job output and error files. Of course you'll probably need input files too ![]() as well as output files.
as well as output files.
Because a single job can create a lot of files, it is a good idea to use a different directory for each job or set of closely related jobs, maybe with a name similar to the job being performed. This will help you stay organized.
Here's an example directory structure
$SCRATCH/my_project
/original # contains or links to original fastq files
/fastq_prep # run fastq QC and trimming jobs here
/alignment # run alignment jobs here
/gene_counts # analyze gene overlap here
/test1 # play around with stuff here
/test2 # play around with other stuff here
Command files in each directory can refer to files in other directories using relative path syntax, e.g.:
cd $SCRATCH/my_project/fastq_prep ls ../original/my_raw_sequences.fastq.gz
Or create a symbolic link to the directory and refer to it as a sub-directory:
cd $SCRATCH/my_project/fastq_prep ln -s ../original fq ls ./fq/my_raw_sequences.fastq.gz
relative path syntax
As we have seen, there are several special "directory names" the bash shell understands:
- "dot directory" ( . ) refers to "here" or "the current directory"
- "dot dot directory" ( .. ) refers to "one directory up"
- "tilde directory" ( ~ ) refers to your home directory
Try these relative path examples:
cd $SCRATCH/core_ngs/slurm/simple ls ../wayness ls ../.. ls -l ~/.bashrc
Interactive sessions (idev)
So we've explored the TACC batch system. What if you want to do some interactive-style testing of your workflow?
Interactive sessions are available through the idev command as shown below. idev sessions are configured with similar parameters to batch jobs.
idev -p development -m 20 -A UT-2015-05-18 -N 1 -n 24
Notes:
- -p development requests nodes on the development queue
- -m 20 asks for a 20-minute session (120 minutes is the maximum for development)
- -A UT-2015-05-18 specifies the TACC allocation/project to use
- -N 1 asks for 1 node and -n 24 requests access to 24 cores
When you ask for an idev session, you'll see output as shown below. Note that the process may pause while it waits for available nodes.
-> Defaults file : ~/.idevrc
-> System : ls5
-> Queue : development (cmd line: -p )
-> Nodes : 1 (cmd line: -N )
-> Total tasks : 24 (cmd line: -n )
-> Time (minutes) : 20 (cmd line: -m )
-> Project : UT-2015-05-1 (cmd line: -A )
-----------------------------------------------------------------
Welcome to the Lonestar 5 Supercomputer
-----------------------------------------------------------------
No reservation for this job
--> Verifying valid submit host (login2)...OK
--> Verifying valid jobname...OK
--> Enforcing max jobs per user...OK
--> Verifying availability of your home dir (/home1/01063/abattenh)...OK
--> Verifying availability of your work dir (/work/01063/abattenh/lonestar)...OK
--> Verifying availability of your scratch dir (/scratch/01063/abattenh)...OK
--> Verifying valid ssh keys...OK
--> Verifying access to desired queue (development)...OK
--> Verifying job request is within current queue limits...OK
--> Checking available allocation (UT-2015-05-18)...OK
Submitted batch job 1579644
-> After your idev job begins to run, a command prompt will appear,
-> and you can begin your interactive development session.
-> We will report the job status every 4 seconds: (PD=pending, R=running).
->job status: PD
->job status: R
-> Job is now running on masternode= nid00011...OK
-> Sleeping for 7 seconds...OK
-> Checking to make sure your job has initialized an env for you....OK
-> Creating interactive terminal session (login) on master node nid00011.
Warning: Permanently added '[nid00011]:6999,[10.128.0.12]:6999' (RSA) to the list of known hosts
Once the idev session has started, it looks quite similar to a login node environment, except for these differences:
- the hostname command on a login node will return a login server name like login2
- while in an idev session hostname returns a compute node name like nid00011
- you cannot submit a batch job from inside an idev session, only from a login node
- your idev session will end when the requested time has expired
- or you can just type exit to return to a login node session